










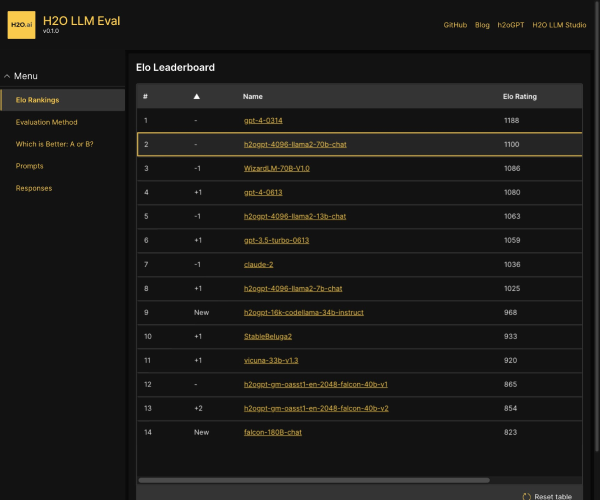

「H2O EvalGPT」是什么
H2O EvalGPT是一款专注于AI模型评估的工具,通过集成化执行仪表板,为用户带来模型对比、深度洞察以及可定制的性能监控体验,以友好的界面助力用户实现对模型的精准评估与调优。
功能解析
- 创建综合执行仪表板:能同时运行多个评估器或评估套件,提供统一视角,方便对不同模型和系统的性能指标进行监控与分析。
- 模型和排行榜对比:可轻松对比不同系统的评估结果,涉及答案相关性、上下文精度、忠诚度、上下文召回率、Ragas分数等多项指标。
- 可配置评估器等:用户能够根据特定需求调整模型参数和评估设置,确保模型主机系统和大语言模型(LLMs)达到最佳性能。
- 深度评估洞察:借助新的评估问题和洞察功能,发现模型的失败状态,及时识别并解决问题,提升模型整体可靠性。
- 测试用例扰动:通过新的测试用例扰动功能,在测试过程中引入可变性,全面评估模型在不同场景下的稳健性。
产品特色
- 推动可信AI发展:通过评估模型的忠诚度和偏差,为提升AI的可靠性和准确性提供技术洞察和可定制的评估器。
- 灵活适应需求:可配置的特性使得模型参数和评估设置能根据独特业务需求进行调整,展现出高度的灵活性。
- 界面友好体验佳:在列表页面、可视化和整体用户界面设计上进行了优化,同时后端的稳健性、安全性和稳定性也得到增强。
应用场景
- 模型研发场景:研发人员在模型开发过程中,利用H2O EvalGPT进行多指标评估和对比,及时发现模型问题并优化,提升模型质量。例如某AI公司在研发新的语言模型时,通过该工具对比不同版本模型的各项指标,不断改进模型。
- 企业选型场景:企业在选择合适的AI模型时,借助H2O EvalGPT对多个供应商的模型进行评估和对比,选择最符合自身业务需求的模型。比如某电商企业在挑选用于客户服务的AI模型时,通过该工具评估不同模型在回答相关性等方面的表现。
使用指南
首先进入H2O EvalGPT界面,在模型评估板块,根据需求选择相应的评估器或评估套件来创建执行仪表板。若要进行模型对比,在模型和排行榜对比功能中选择需对比的模型。若需调整参数,在可配置评估器区域进行模型参数和评估设置的调整。利用评估问题和洞察功能以及测试用例扰动功能进行深入评估。
相关导航


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号