











「SuperCLUE」是什么
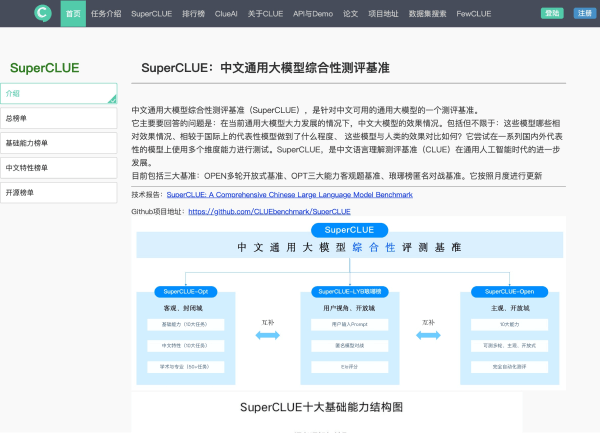
SuperCLUE是中文通用大模型综合性测评基准,是中文语言理解测评基准(CLUE)在通用人工智能时代的进一步发展。旨在了解中文大模型在当下的效果情况,通过多维度能力对国内外代表性模型进行测试。
功能解析
- 语言理解与抽取:可理解并解析文字信息含义,抽取关键信息与主题。
- 闲聊:能与用户进行自由、自然且符合语言习惯的对话。
- 上下文对话:理解并记住对话信息,保持回答连贯性。
- 生成与创作:创造文章、文案等新文本内容。
- 知识与百科:像百科全书一样提供知识信息。
- 代码:理解和生成编程代码,解决编程问题。
- 逻辑与推理:理解和应用逻辑原则进行推理。
- 计算:执行数学运算,解决数学问题。
- 角色扮演:在模拟环境中扮演角色并做出适当反应。
- 安全:防止生成敏感或不适当内容。
产品特色
- 多维度能力测试:从语言、知识、专业等多方面能力对模型进行测试,全面评估模型表现。
- 多轮对话评测:部分能力测试通过多轮对话示例进行,能更好考察模型在实际对话场景中的能力。
- 持续更新:按照月度进行更新,紧跟模型发展动态。
应用场景
- 大模型研发场景:研发人员通过SuperCLUE的测试结果,了解模型优势与不足,有针对性地优化模型。例如在模型语言生成能力较弱时,可改进训练策略。
- 模型选型场景:企业或机构在选择大模型应用时,借助SuperCLUE测评结果,挑选最适合自身需求的模型。如需要强大知识问答能力的场景,可参考知识与百科能力测试结果。
技术原理解析
SuperCLUE通过在一系列国内外代表性的模型上,运用多个维度能力进行测试,从而得出模型的各项测评数据,以评估模型在不同方面的表现。
使用指南
目前可通过访问Github项目地址(https://github.com/CLUEbenchmark/SuperCLUE )获取相关信息,也可通过联系邮箱(CLUEbenchmark@163.com )进行咨询。
相关导航


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号