











「Doc2X」是什么
Doc2X是一款由AI驱动的智能文档处理工具。它凭借先进的解析技术,能精准识别多种类型文档中的内容,为用户带来高效智能的文档处理体验,满足多领域的多样化需求。
功能解析
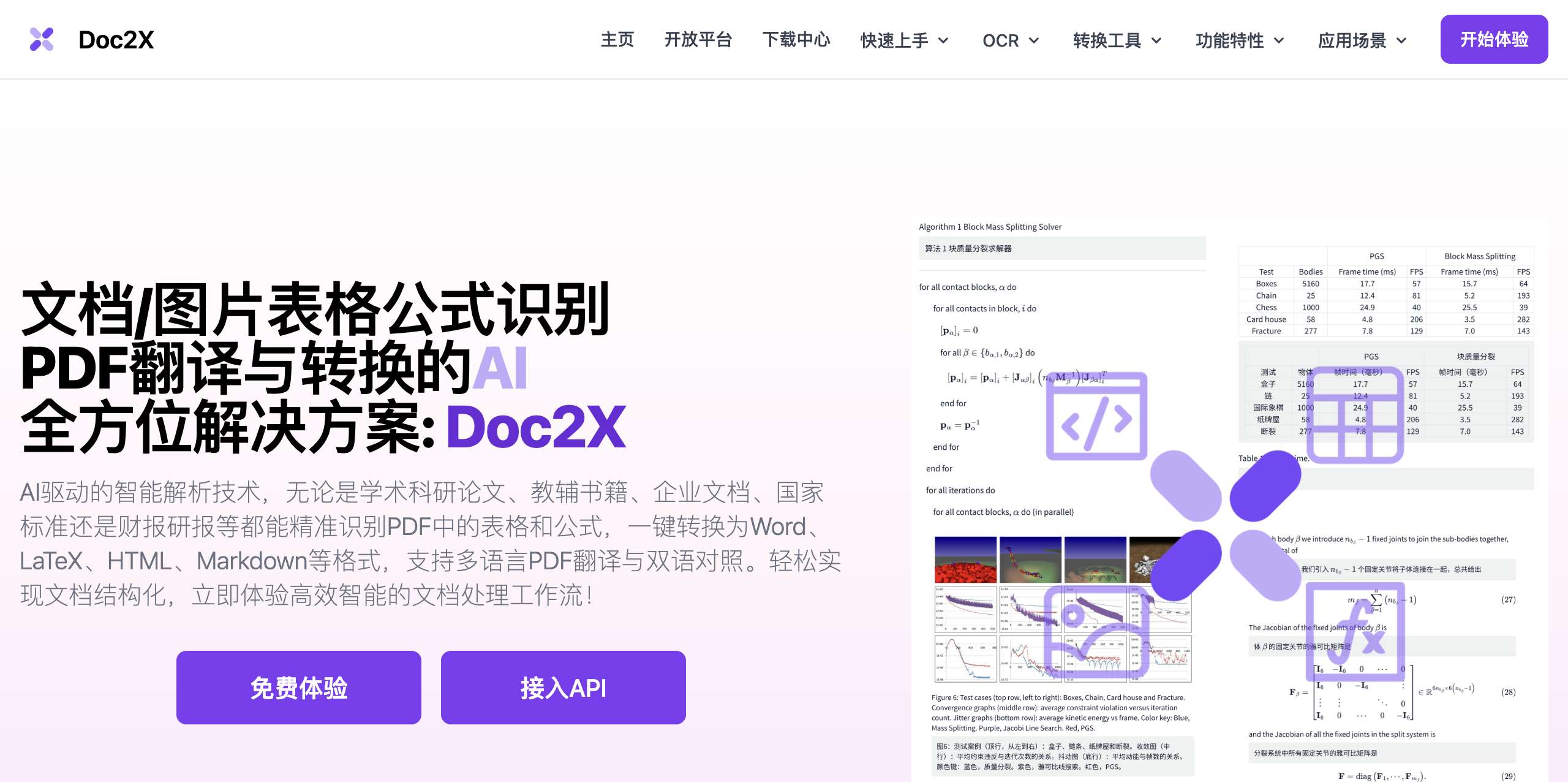
- 精准识别:无论是学术科研论文里的复杂公式、企业文档中的复杂表格,还是手写笔记中的公式,都能高精度识别,准确转化为可编辑格式。
- 多格式转换:可轻松将PDF转换为Word、HTML、LaTeX、Markdown等多种格式,转换前还能与原PDF对照跳转编辑,保证准确性。
- 多语言PDF翻译:支持GPT、Deepseek、GLM等多种AI引擎进行双语对照翻译,提供沉浸式翻译体验,且保留原版排版。
- 图片公式识别编辑:集成多个模型实现图片公式识别,支持对照编辑与转换,有丰富模板。
- 文档大模型AI对话:基于文档上下文进行AI对话,可快速定位关键信息,支持多轮深度问答、智能总结,还能原文跳转。
- 高效批量处理:提供批量识别转换功能,可接入API实现批量快速识别PDF。
产品特色
- 识别精度高:采用大模型OCR技术,对复杂公式和表格精准还原,算法持续迭代提升精度。
- 多模型支持:在翻译和图片公式识别等功能上,支持多种大模型,满足不同需求。
- 保留原版排版:翻译时能完美保留原文版式和布局,方便阅读和再编辑。
- 安全有保障:严格遵守隐私协议与数据安全标准,对上传文档加密处理,用户可选择删除临时文件。
应用场景
- 学术科研场景:研究人员面对学术论文PDF,可通过Doc2X精准提取复杂公式、表格为可编辑格式,加速论文整理与数据统计,专注创新发现。如某高校科研团队使用后,论文数据整理时间缩短一半。
- 教育机构场景:教师处理教辅资料、教材习题时,借助Doc2X快速数字化转化与翻译,轻松制作电子课件和在线题库。
- 国家标准与金融研报机构场景:可将国家标准、行业财报研报中的数据表格与规范文本进行结构数字化,助力企业知识库建设与数据分析。
- 出版社与媒体场景:能把纸质图书、期刊中含公式与数据的PDF转化为电子可编辑格式,便于出版审校、电子书发行以及数据新闻报道。
- 翻译与国际合作场景:多语言PDF快速翻译与双语对照功能,为跨国团队、国际会议及文献交流提供流畅沟通体验。
使用指南
若想使用Doc2X,可通过主页“免费体验”直接试用在线工具。若想接入API,在“接入API”处查看详细文档与示例。使用时,先上传文档,根据需求选择相应功能,如识别、转换或翻译等操作即可。
相关导航



AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号