











「OmniHuman-1」是什么
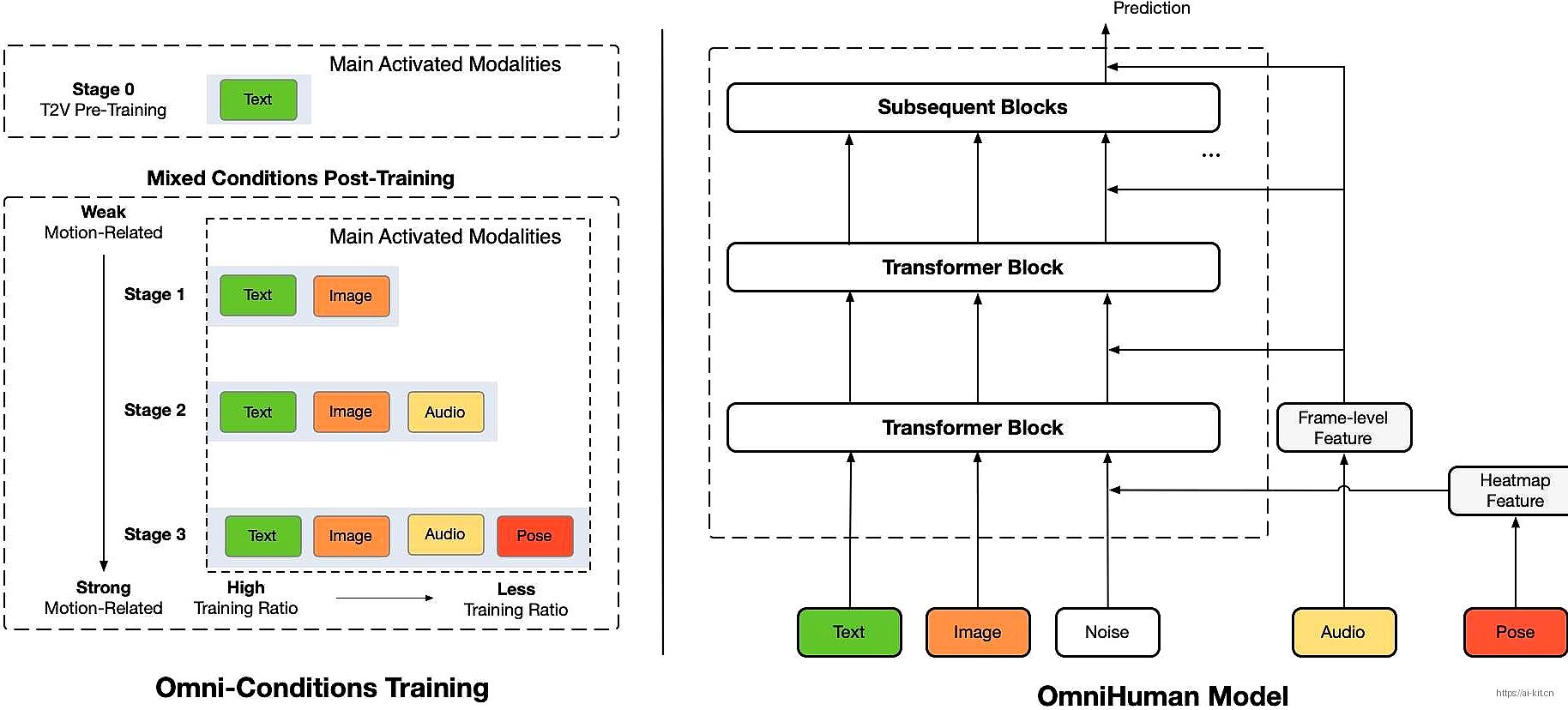
OmniHuman-1是一个端到端的多模态条件人体视频生成框架,它能基于单个人体图像和运动信号(如仅音频、仅视频或音频视频组合)生成人体视频。其独特优势在于通过引入多模态运动条件混合训练策略,让模型从混合条件的数据扩展中受益,克服了以往高质量数据稀缺的问题,能为用户带来逼真的人体视频生成体验。
功能解析
- 多模态生成:可根据单个人体图像和不同运动信号生成人体视频,无论是音频、视频还是两者结合都能处理。比如在一些创意视频制作中,仅需提供人物图片和合适音频,就能生成对应视频。
- 多风格支持:支持各种视觉和音频风格,能生成任意宽高比和身体比例的逼真人体视频,从肖像到半身、全身,在运动、灯光和纹理细节等方面都很真实。像在不同风格音乐的MV制作中,可适配多种风格需求。
产品特色
- 混合训练策略:采用多模态运动条件混合训练策略,这是区别于其他产品的独特技术,使得模型能利用混合条件数据扩展优势,克服数据稀缺问题,在面对不同输入时能生成更优质内容。
- 输入多样性:支持输入卡通、人造物体、动物以及具有挑战性的姿势等,且能确保运动特征与每种风格独特特点相匹配,满足了用户多样化的创作需求。
应用场景
- 音乐创作场景:在音乐创作领域,用户制作歌曲MV时,可能面临找不到合适演员或者拍摄成本高等问题。OmniHuman-1能依据歌曲音频和人物图片,生成对应MV片段,不管是何种音乐风格,都能适配,极大降低了创作成本。比如制作一首古风歌曲MV,仅需提供古风人物图片和歌曲音频即可生成合适视频。
- 影视特效场景:影视制作中,一些特效场景可能需要虚拟人物的动作配合,传统方式制作复杂且成本高。OmniHuman-1可以通过视频驱动或音频视频结合驱动,生成符合特效场景要求的人体动作视频,提高制作效率。如在科幻电影中制作虚拟外星人的动作视频。
使用指南
首先上传单个人体图像,然后选择对应的运动信号(音频、视频或两者结合),接着根据需求选择视频的风格和宽高比等参数,最后点击生成按钮,即可得到OmniHuman-1生成的人体视频。
相关导航





AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号