春节假期,科技产品DeepSeek热度飙升。即便平时对科技新闻不关注的长辈,也对其有所耳闻,上次引发如此高关注度的AI大模型还是OpenAI的ChatGPT。
然而,大红大紫背后,DeepSeek遭受连续高强度网络攻击,官网常无法正常生成内容,即便关闭联网搜索,具备深度推理能力的DeepSeek-R1在线模型也受影响。好在有华为等科技公司支持,第三方平台接入DeepSeek的API,让稳定在线使用成为可能。
有人不满足于线上访问,如小雷就想在春节期间把DeepSeek大模型部署到本地。实践后发现,打造“AI电脑”并非易事。
无论何种大模型,在本地部署,难点在于获取对应资源和命令。且本地大模型虽为训练好的成品,但需一定硬件基础才能有好体验。
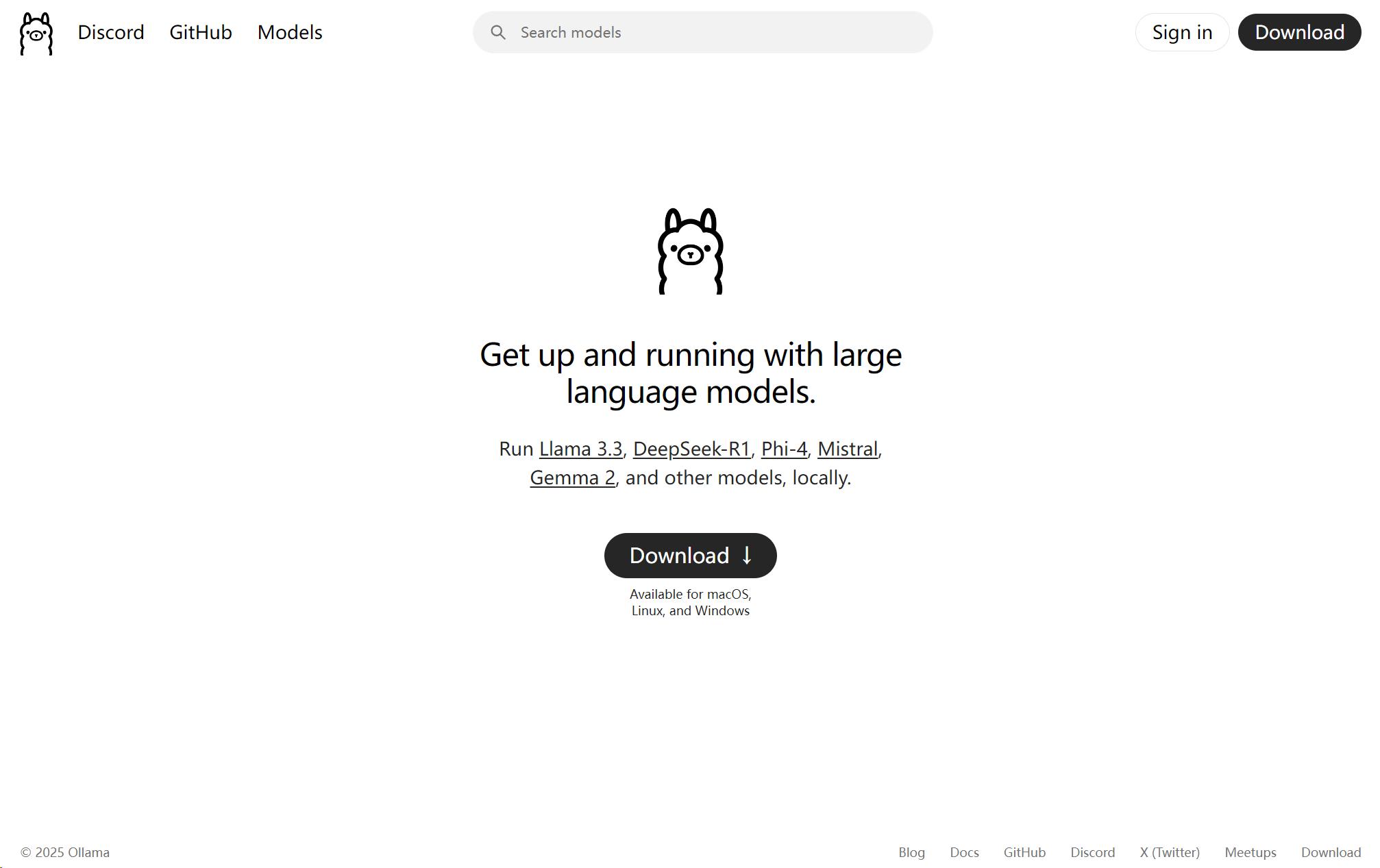
首先可到Ollama官网下载桌面端应用,它像承载本地大模型的“容器”,在其模型库中,除DeepSeek外,还有许多开源大模型。
Ollama桌面端无控制界面,下载大模型需在官网模型库找到对应代码,复制到PowerShell中执行数据拉取和安装。
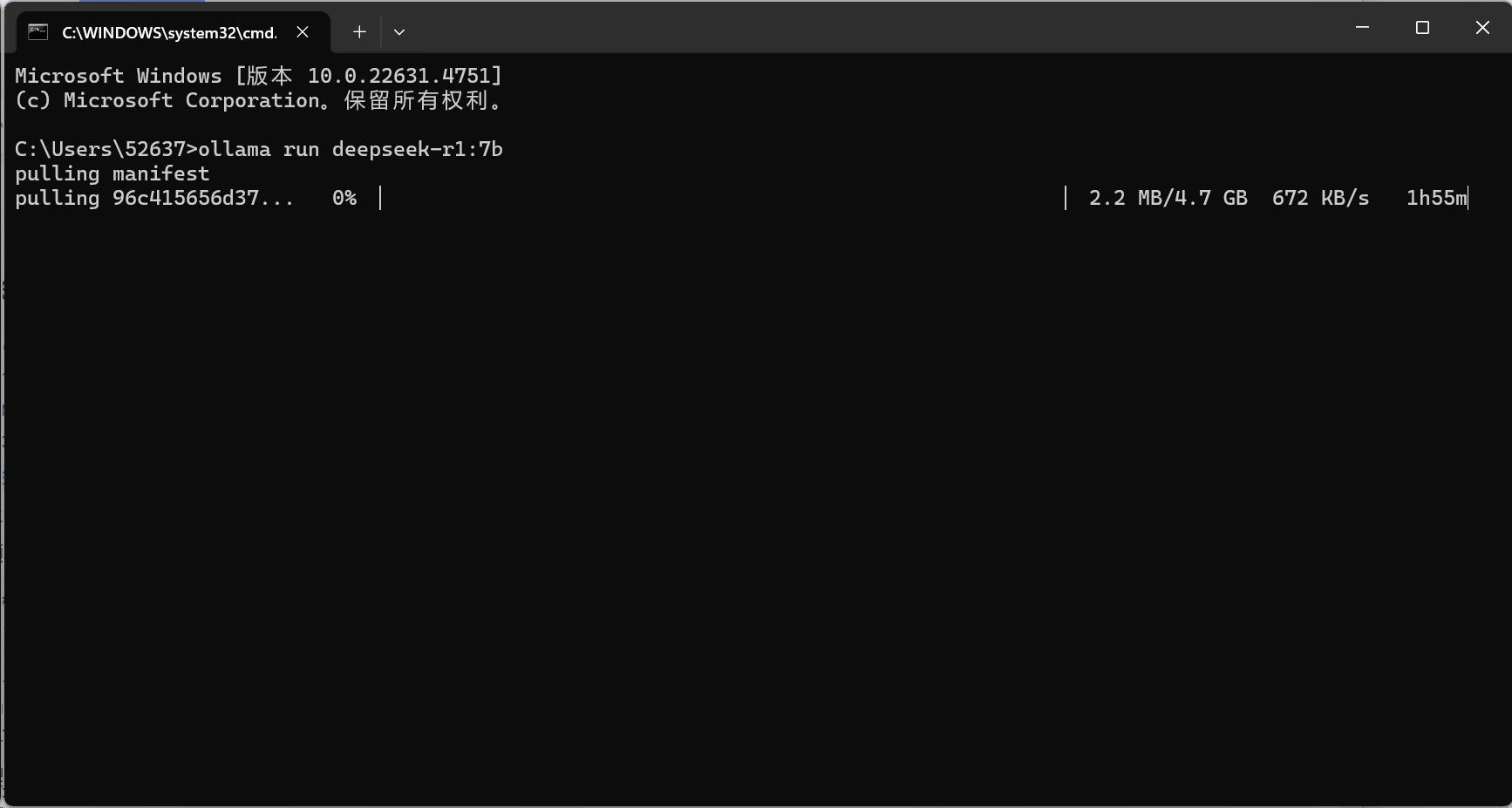
小雷选的是DeepSeek-R1模型的7b版本,有70亿参数,占用4.7GB。本地大模型参数量越大,语言理解、文本生成等能力越强,但对电脑计算能力要求也越高。
一般运行1.5B参数模型,最低需4GB显存GPU和16GB内存,否则用CPU计算,负担大且推理时间长。满血版DeepSeek-R1参数量为671b,体积达404GB,个人部署选1.5b- 8b参数较合适。
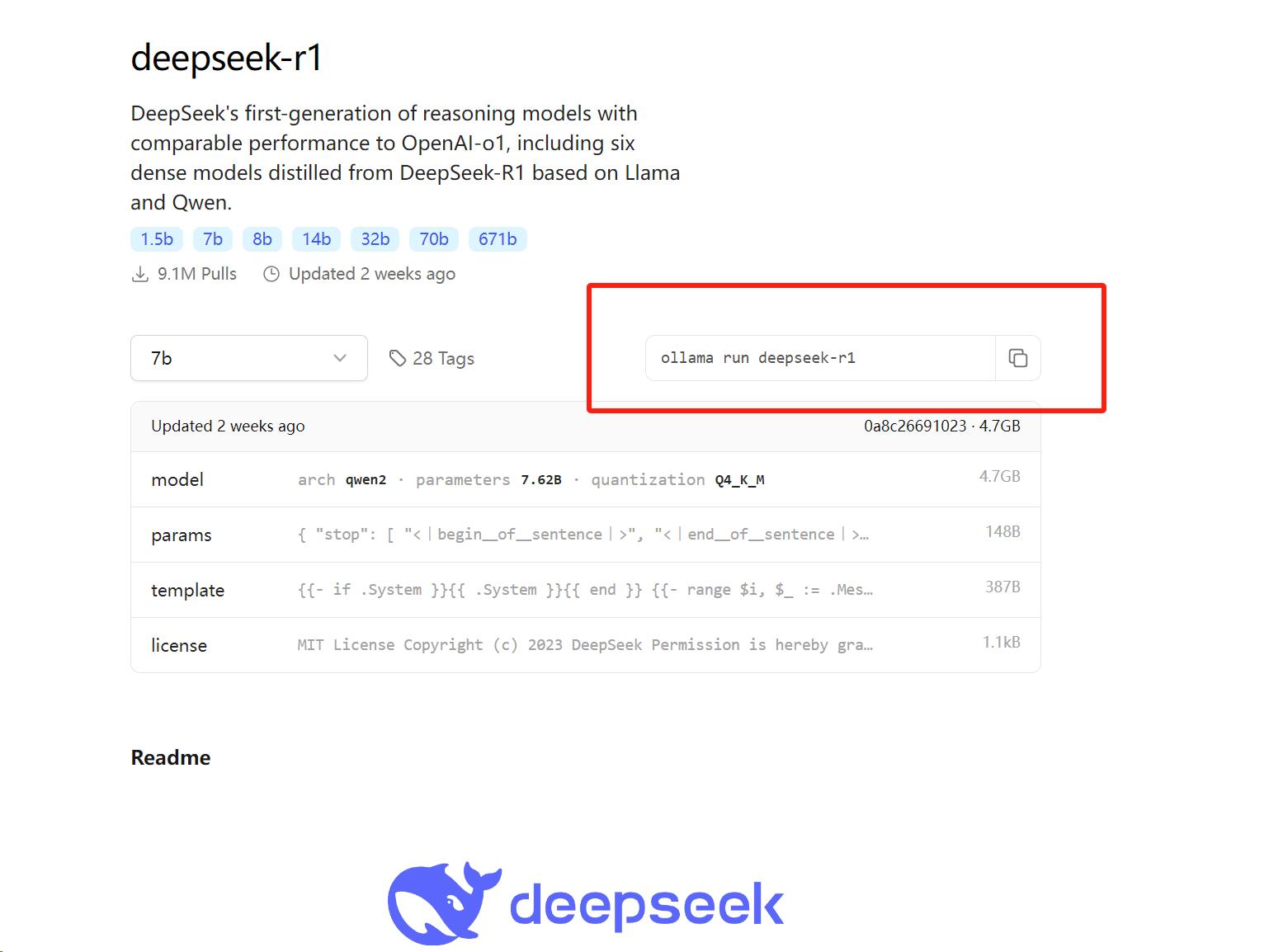
模型数据拉取后自动安装,完成后可在PowerShell窗口调取DeepSeek-R1模型,输入问题即可推理生成。
不过,每次开机都要打开PowerShell激活大模型,对普通用户不便。小雷在Docker应用上添加Open-WebUI组件,让DeepSeek-R1能通过浏览器交互,并具备联系上下文能力。
需先下载Docker桌面端并完成安装,再打开PowerShell界面复制执行相应指令。使用NVIDIA GPU的用户指令不同。
拉取大模型文件和Open WebUI组件耗时较长,网络不佳时可能出现下载进度丢失问题。
安装完成后,在Docker应用中勾选启动Open-WebUI组件,点击链接可跳转网页,此时就拥有了“AI电脑”。
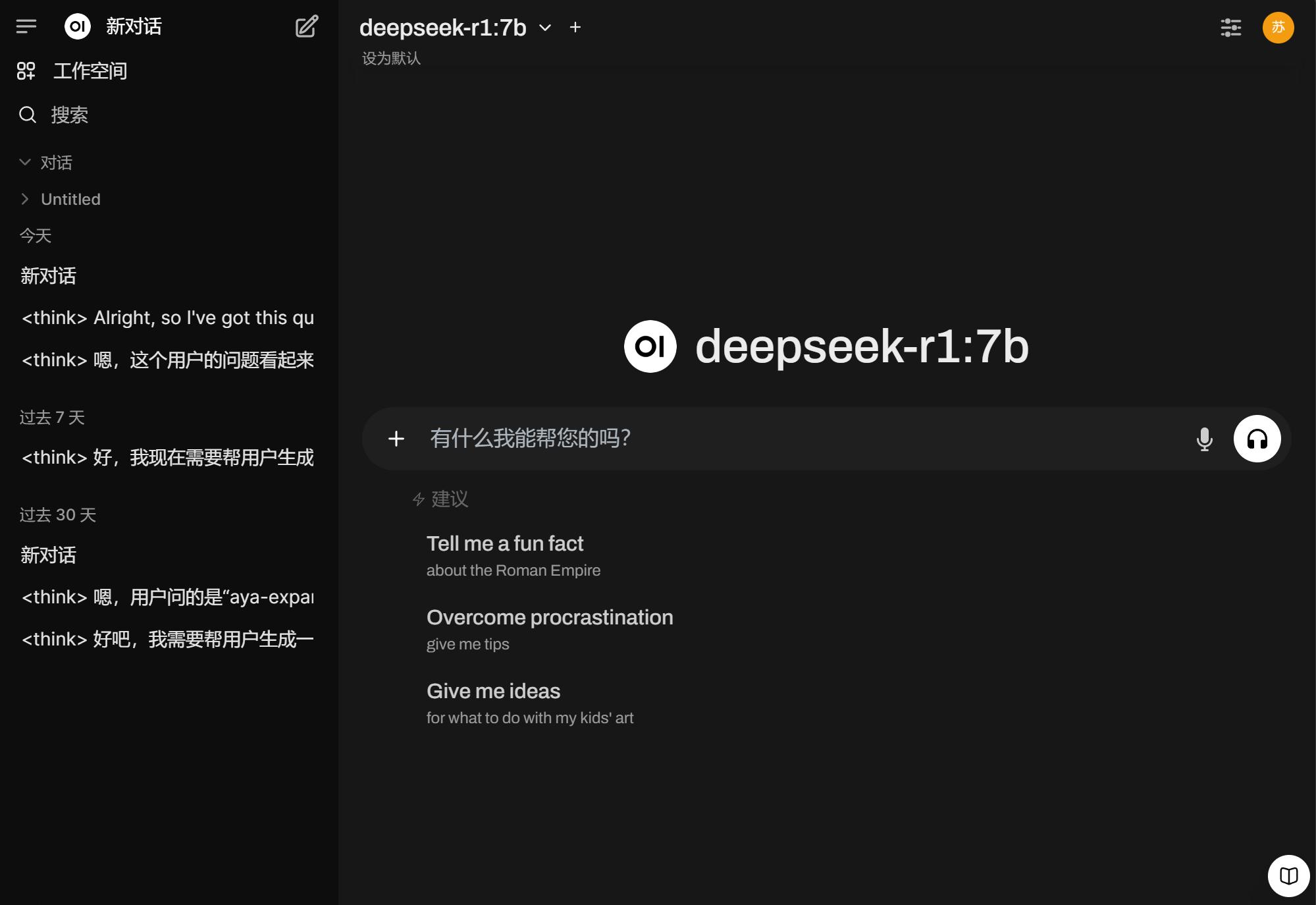
小雷体验发现,部署步骤不算复杂,主要耗时在搜索命令行、安装资源及拉取安装组件上。Ollama和Docker可通过百度搜索,有兴趣和动手能力的用户可尝试。
当然,本地部署大模型方法不止一种,如华为的ModelEngine,具备一站式训练优化和一键部署能力,面向企业端开发。
国内AI大模型网页端服务齐全,本地部署意义何在?一方面,本地大模型数据和对话记录离线存储,推理响应快,可避免敏感内容泄露,在无网环境也能使用;另一方面,支持开源模型,用户可灵活扩展切换、优化集成,操作空间大。
小雷用机械革命无界14X安装DeepSeek-R1 7b模型,该电脑无独立显卡,不在推荐配置内。这导致模型生成内容需更多推理时间和资源占用。
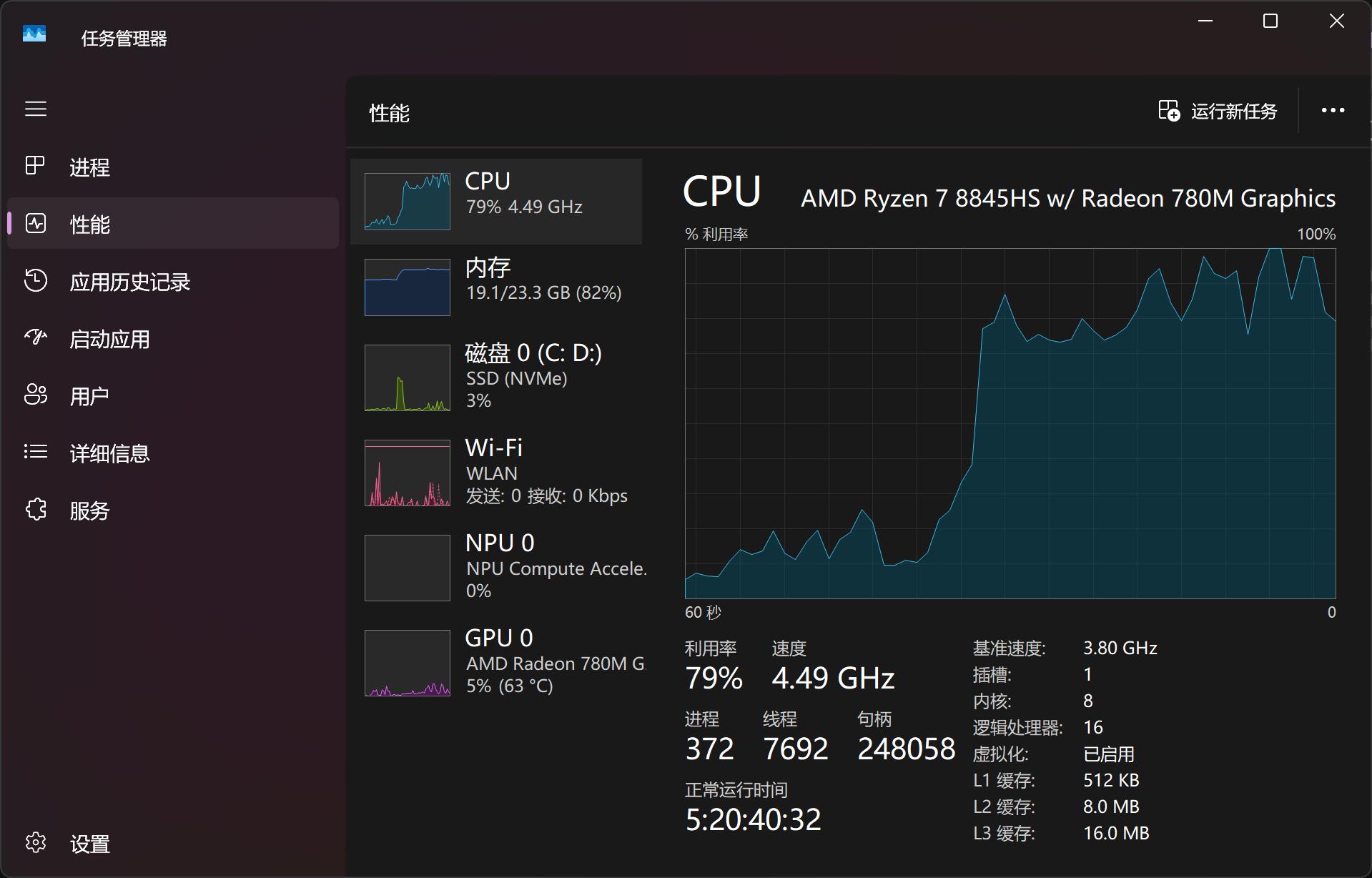
如讨论“饭后胀气”问题,大模型思考30秒 – 1分钟才能生成答案,期间电脑负载高,CPU和内存几近占满。但答案有一定参考价值。

小雷对DeepSeek拟人化思考过程感兴趣,其推理过程能激发普通用户兴趣。将同样问题放在网页端,出现“服务器繁忙”反馈,此时本地部署虽能力不强,但至少能访问。
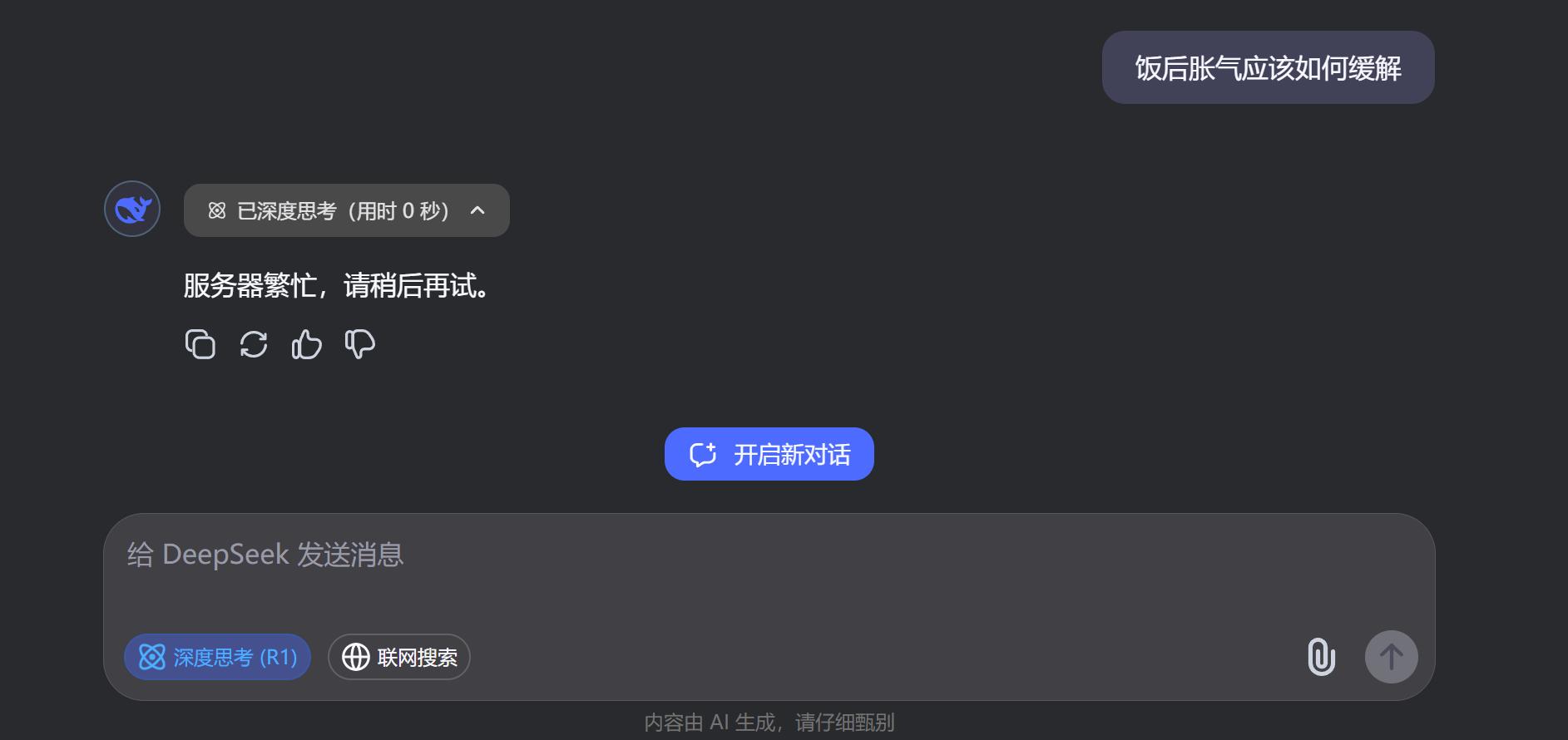
用概率题提问本地DeepSeek-R17b,网页端持续繁忙,本地模型列举多种情况后混入之前问题内容,未给出答案。只能说数学题对其较复杂,本地大模型推理时电脑负载大。

从开源角度,本地大模型扩张性和可玩性强,但部署不易,需动手能力强的用户挖掘玩法。
现阶段,本地大模型生成能力难与线上媲美,适合动手能力强的电脑用户折腾,能带来功能便利,但普通用户部署有难度。

小雷部署本地DeepSeek大模型只为新鲜,平均生成用时20秒起步,除离线使用外,普通生成需求体验不如在线大模型。
读取文件分析、联网收集数据分析等能力需用户自行折腾,删除大模型数据也需学习步骤,否则会占系统盘空间。
DeepSeek走开源道路,主要是为打响市场影响力,占据市场地位,吸引行业围绕建立服务体系。国内众多大模型平台接入其API就是开源成果。
未来,DeepSeek完成行业应用渗透后,个人本地部署可能变简单。至于其发展如何难以预测,虽服务不稳定是短痛,但提高市场占比后,本地部署或许不再必要。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号