DeepSeek的招聘举动引发了广泛关注,一举登上热搜首位。此次招聘开出的薪资条件极为诱人,从BOSS平台最初公布的在招岗位信息可知,最高薪资达110k×14,本科岗位最高也有90k×14。就连实习生也是500元一天起招,按每月20天算可月入万元,最高日薪达一千元。如此高薪,难怪众多网友羡慕不已。
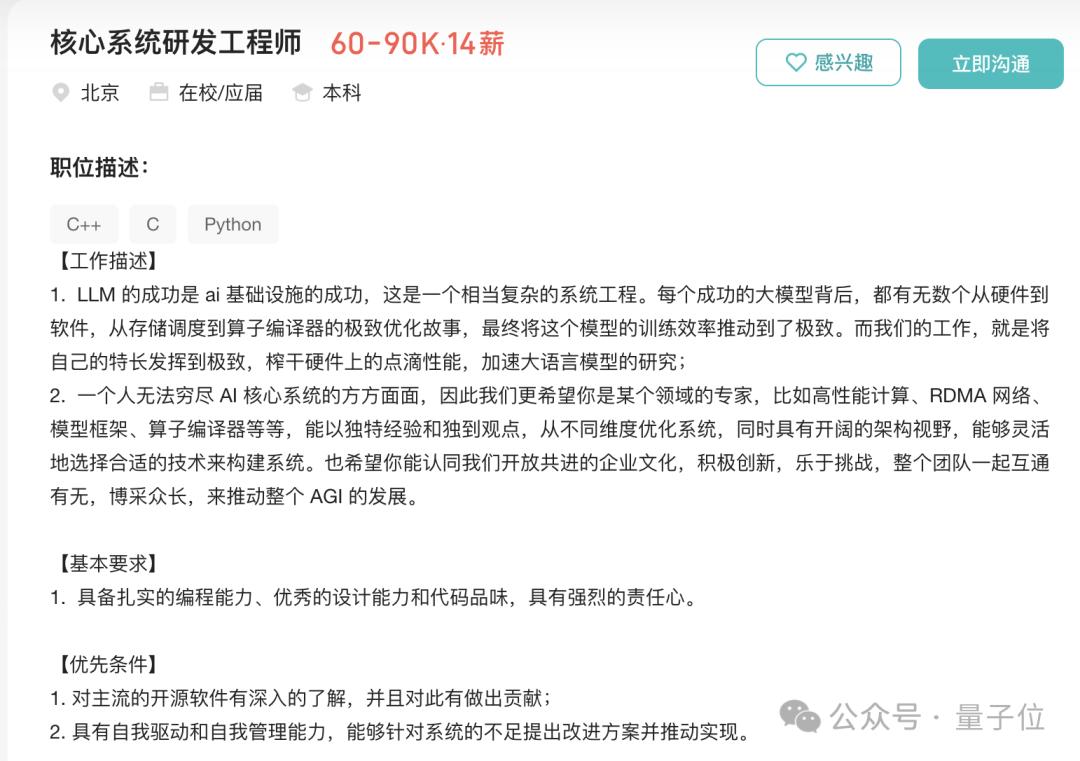
DeepSeek的招聘要求别具一格,除个别岗位需硕士学历外,大多本科起招,且不论专业、有无工作经验,均可应聘。以核心系统研发工程师岗位为例,90K、14薪,年薪达126万,同样本科起步。其既有团队也十分年轻,去年初推出V2时就引起业内关注,当时Anthropic联创认为背后有“高深莫测的奇才”,但DeepSeek创始人梁文锋否认了这一说法,称团队成员多为应届毕业生、在读博四、博五实习生以及毕业才几年的年轻人。
如今的v3和R1阶段,应届生和在读生,尤其是清北的应届生表现活跃。为DeepSeek提出新型注意力MLA(多头潜在注意力)、GRPO强化学习对齐算法等关键创新的都是年轻人。甚至有实习生也取得重要成果,如被顶会ICLR2025接收的一篇论文,其第一作者是DeepSeek的大四实习生,通过强化学习和蒙特卡洛树搜索研发的数学证明模型,在相关数据集上通过率远超GPT-4。
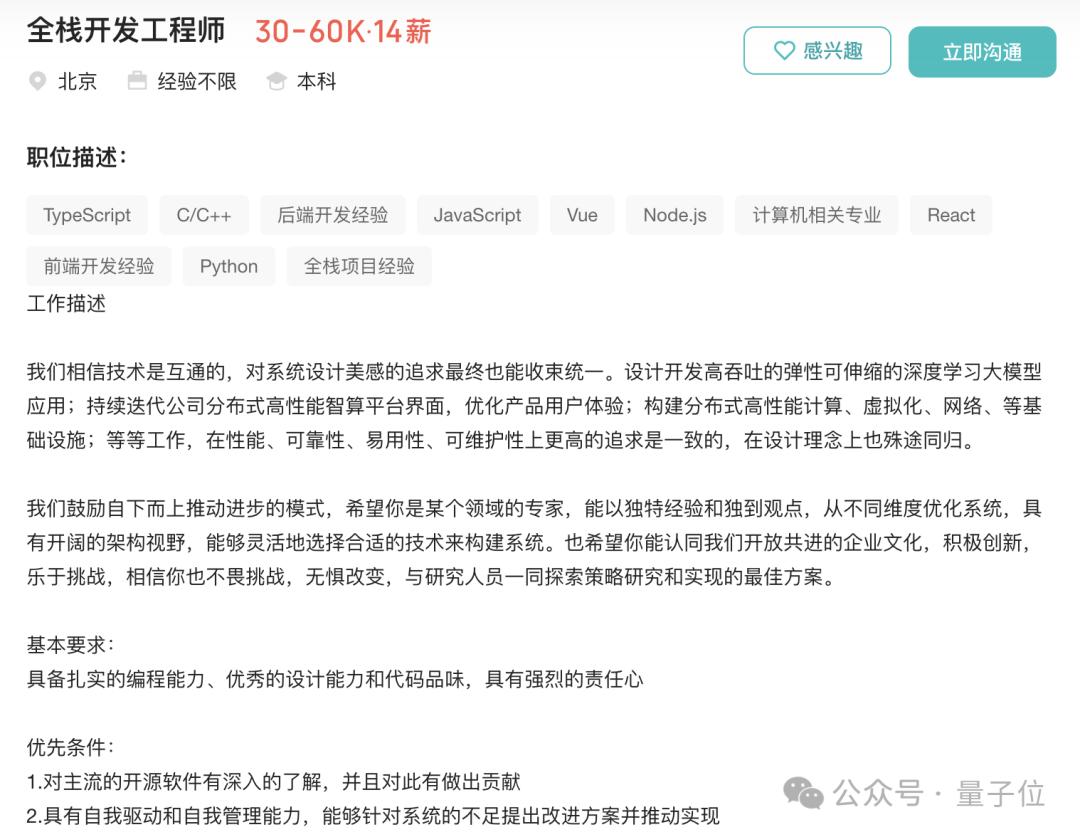
从岗位维度看,“全栈工程师”在DeepSeek招聘列表中占比可观,且岗位描述限制少。梁文锋介绍,员工入职后开启“放养模式”,不设KPI、不干预,人员和算力需求都能得到满足,每个人对卡和人的调动不设上限,有想法可随时调用训练集群的卡无需审批,还能灵活调用人员。MLA注意力机制的诞生就是团队支持创新想法的例证。
DeepSeek在人才和算力资源上不惜成本。据知名半导体研究机构Semianalysis报告推测,DeepSeek拥有约5万块HopperGPU,GPU投资超5亿美元,还拥有约1万个H800和1万个H100,并订购了更多H20,这些GPU在幻方量化和DeepSeek间共享。报告还指出,“DeepSeekV3训练成本仅600万美元”的说法片面,硬件支出远超5亿美元,开发新架构需大量资金和算力,如MLA机制前期投入大,但后期降本效果显著。正因如此,DeepSeek在性价比上有想象空间,吸引了各大云计算平台争抢上架其模型,这也使得它开出天价招聘人才不那么令人意外。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号