











「AnyV2V」是什么
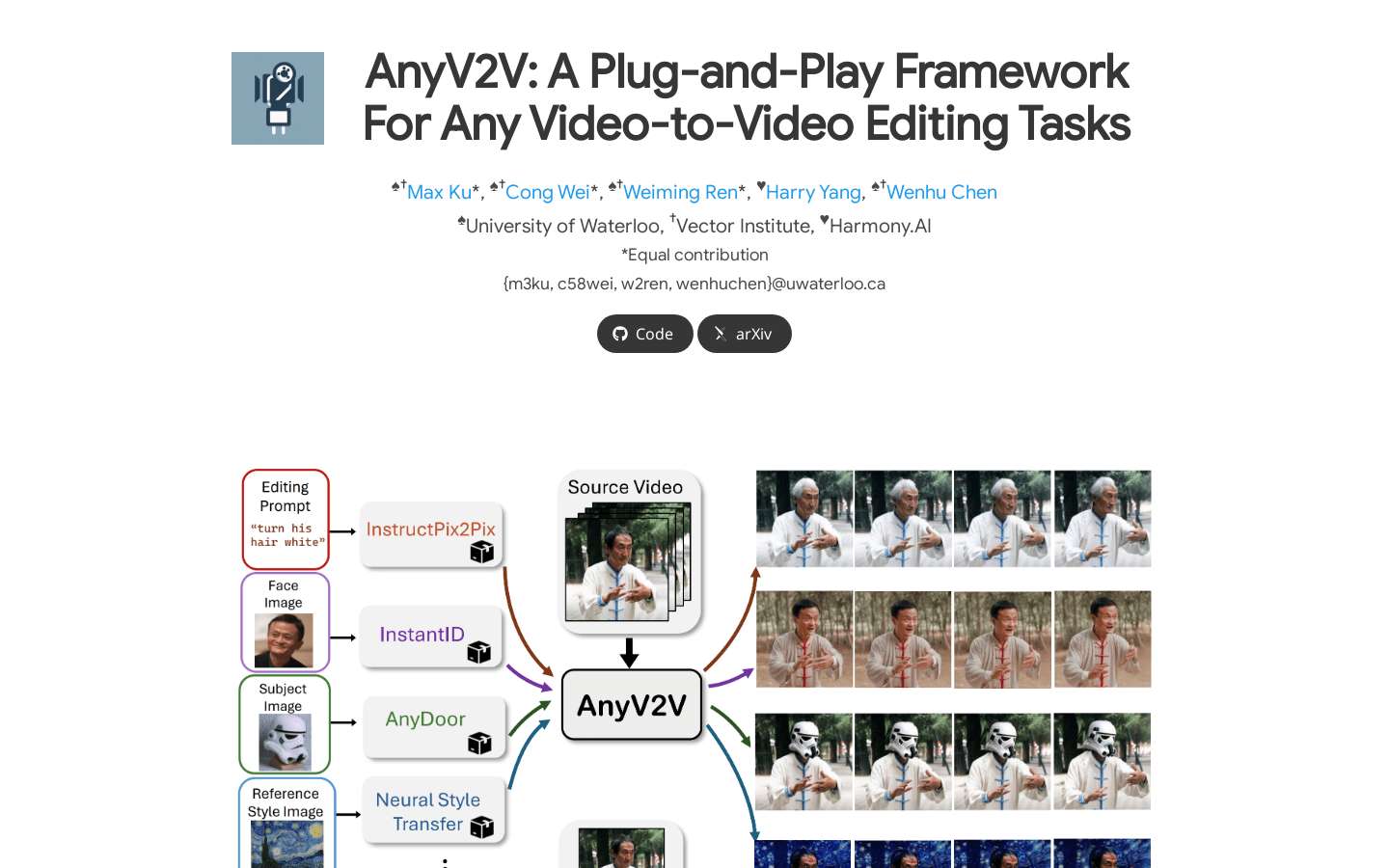
AnyV2V是一款新颖的无需调优的框架,旨在将视频编辑简化为两个主要步骤,能利用现有的图像编辑工具支持各种视频编辑任务,还能支持任意视频长度,为用户带来全新的视频编辑体验。
功能解析
- 基于提示编辑:在各种局部编辑任务中表现出色,能保持背景不变,生成结果与文本提示高度契合,还能维持较高的运动一致性。
- 主体驱动编辑:配备AnyDoor的AnyV2V可在视频中用目标主体替换对象,同时保持视频运动和背景不变。
- 风格转换:使用NST / InstantStyle对第一帧进行风格编辑,能将任何参考风格无缝转移到视频上。
- 身份操纵:集成InstantID,可使用单参考面部图像在视频中交换人物身份。
- 长视频编辑:可在I2V模型的训练帧之外执行视频编辑。
产品特色
- 无需调优:打破传统视频编辑模型需大量微调的局限,简化视频编辑流程,节省时间与精力。
- 灵活编辑:可利用任意现有图像编辑工具,支持多种编辑任务,包括基于提示编辑、基于参考的风格转换等,满足多样创意需求。
- 效果出色:在自动和人工评估中显著优于其他基线方法,能在所有编辑任务中实现高质量编辑的同时,与源视频保持视觉一致性。
应用场景
- 创意视频制作场景:视频创作者在制作创意视频时,常面临难以实现独特创意效果,以及保持视频连贯性的问题。AnyV2V能实现如“下雪效果添加”“人物风格转换”等各种创意编辑,还能维持视频运动和背景不变,确保连贯性,助力创作者轻松产出有创意且优质的视频。
- 影视后期制作场景:影视后期制作中,对视频画面风格统一、人物身份替换等有较高要求。AnyV2V的风格转换和身份操纵功能,能无缝转移参考风格,精准替换人物身份,提高制作效率与质量,为影视创作提供有力支持。
技术原理解析
AnyV2V将视频编辑过程分为两个阶段。第一阶段对第一帧图像进行编辑,得益于现有的众多图像编辑模型,可实现精细修改与灵活应对各种编辑任务。第二阶段是图像到视频的重建,先将源视频反转成初始噪声,再用DDIM采样进行去噪,采样过程中从图像到视频的解码器层提取空间特征、空间注意力和时间注意力,最后通过固定潜在变量并以编辑后的第一帧作为条件信号进行DDIM采样,将特征和注意力注入模型的相应层来生成编辑后的视频 。
使用指南
首先输入源视频,根据编辑任务在第一阶段对第一帧应用黑盒图像编辑方法。接着进入第二阶段,将源视频反转成初始噪声,利用DDIM采样去噪,采样时从图像到视频的解码器层提取相应特征和注意力。最后,固定潜在变量,以编辑后的第一帧作为条件信号进行DDIM采样,将特征和注意力注入模型相应层,完成视频编辑。
相关导航




AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号