











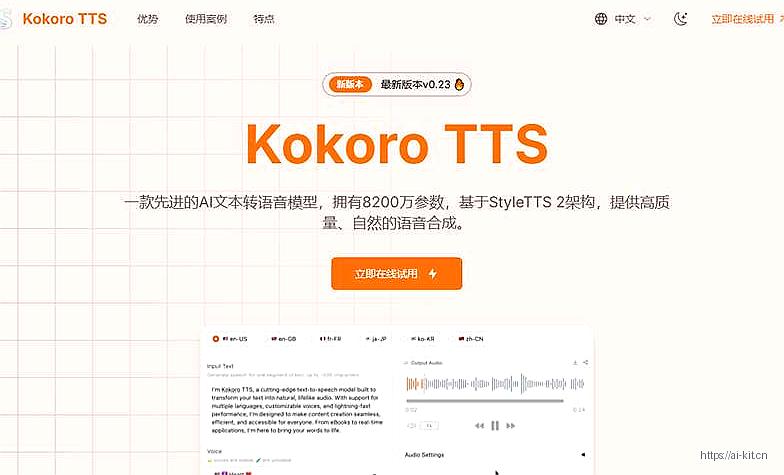
「Kokoro TTS」是什么
Kokoro TTS是一款前沿的人工智能文本转语音模型,基于StyleTTS 2架构构建,仅用8200万个参数,就能实现高质量、自然逼真的语音合成,为用户带来出色的语音体验。
功能解析
- 高效语音合成:凭借8200万参数实现卓越的语音合成质量,相比大型模型,更轻巧且资源高效,能快速生成语音。
- 多语言支持:支持包括美式英语、英式英语、法语、韩语、日语和中文普通话等多种语言,满足全球不同内容创作需求。
- 自定义语音包:提供多个逼真、稳定的语音选项,可依据项目独特需求挑选合适语音风格。
- 自动内容分段:具备自动章节和段落检测功能,将电子书和文章转为音频时更简便,使书面文本转化为条理清晰的音频。
- 兼容OpenAI语音端点:与OpenAI API无缝集成,开发者和内容创作者能扩展其功能,应用场景更广泛。
- 实时音频生成:由NVIDIA GPU加速,实现超快速音频生成,无论大小项目,都能实时合成高质量音频。
产品特色
- 参数高效性能强:Kokoro TTS虽参数规模小,但性能出色,在效率和表现上超越诸多大型模型,如XTTS(46700万参数)和MetaVoice(12亿参数),以高效架构和优质训练数据实现高水准语音合成。
- 开源免费无限制:遵循Apache 2.0许可开源,商业和个人使用均免费,开发者可自由集成到应用中,降低开发成本。
- 多语言拓展潜力大:当前针对英语优化,但其架构设计支持未来语言扩展,后续更新将带来更广泛语言支持。
- 系统适配性良好:高效运行于CPU和GPU环境,支持在Docker和ONNX等平台部署,方便在各种环境集成使用。
应用场景
- 有声书创作场景:数字出版商能借助Kokoro TTS将电子书库轻松转化为高质量有声书,特别是小众题材。比如某数字出版商利用其多语言自然语音,为读者提供丰富有声书资源。
- 培训材料制作场景:企业培训师可使用Kokoro TTS为全球团队创建培训资料,生成清晰自然的多语言配音,节省时间和成本。
- 教育内容分享场景:教育博主用Kokoro TTS为教育博客文章提供音频版本,方便偏好听书的人群获取知识。
- 播客创作场景:播客创作者借助Kokoro TTS从书面脚本快速创建播客剧集,其逼真语音和快速音频生成速度令人称赞。
使用指南
若想使用Kokoro TTS,可从Hugging Face克隆Kokoro TTS仓库,依照提供的设置说明操作。若想快速实现,还有详细的Colab笔记本可供参考指引。
相关导航


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号