











「Phenaki」是什么
Phenaki是一款能够实现从文本生成视频的模型,它支持随着时间变化的提示词输入,可生成长达数分钟的视频,为用户带来全新的视频创作体验。
功能解析
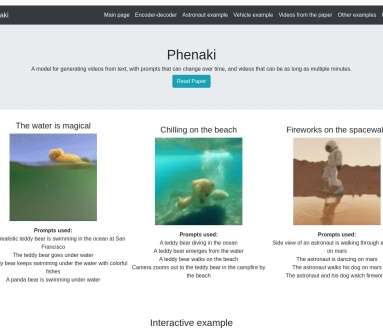
- 文本生成视频:用户输入文本提示词,Phenaki就能将其转化为对应的视频内容。比如输入“A photorealistic teddy bear is swimming in the ocean at San Francisco”等一系列提示词,可生成相关主题视频。
- 支持动态提示词:提示词能随时间变化,让生成的视频内容更加丰富和具有情节性。
- 从静图加提示生成视频:输入首张图片加上提示词,就能生成视频,为创作提供更多可能性。
产品特色
- 独特的模型架构:引入新的因果模型学习视频表示,将视频压缩为离散标记的小表示,且标记器在时间上使用因果注意力,可处理可变长度视频。
- 出色的性能表现:与之前的视频生成方法相比,Phenaki能在开放领域中根据提示序列生成任意长度的视频,在时空质量和每个视频的标记数量方面超越目前文献中所有逐帧基线。
- 数据处理优势:通过对大量图像 – 文本对以及少量视频 – 文本示例的联合训练,实现超越视频数据集现有内容的泛化能力。
应用场景
- 创意视频创作场景:创作者在构思故事性视频时,面临缺乏灵感和快速实现创意的问题。Phenaki可根据创作者输入的一系列提示词,快速生成具有情节变化的视频,如输入一系列关于宇航员在火星上活动的提示词,就能生成有趣的视频内容,为创作者提供创意参考和素材。
- 广告宣传视频制作场景:广告团队制作广告时,需要快速制作出吸引人的视频样片。Phenaki能依据广告主题相关的文本描述,迅速生成视频,如输入关于未来城市和产品特点的提示词,生成带有产品展示的未来城市风格广告视频样片,节省制作时间和成本。
技术原理解析
为解决从文本生成视频的计算成本、高质量文本 – 视频数据量有限以及视频长度可变等问题,Phenaki引入新的因果模型学习视频表示,将视频压缩为离散标记的小表示。标记器在时间上使用因果注意力,可处理可变长度视频。通过双向掩码变换器,以预计算的文本标记为条件生成视频标记,最后将生成的视频标记去标记化创建实际视频。同时,通过对大量图像 – 文本对以及少量视频 – 文本示例的联合训练,提升泛化能力。
使用指南
首先,进入Phenaki的操作界面。然后,在输入框中输入想要生成视频的文本提示词,可根据需求设置视频相关参数。接着,点击生成按钮,等待Phenaki依据提示词生成视频内容。最后,生成完成后,可对生成的视频进行查看和下载等操作。
相关导航





AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号