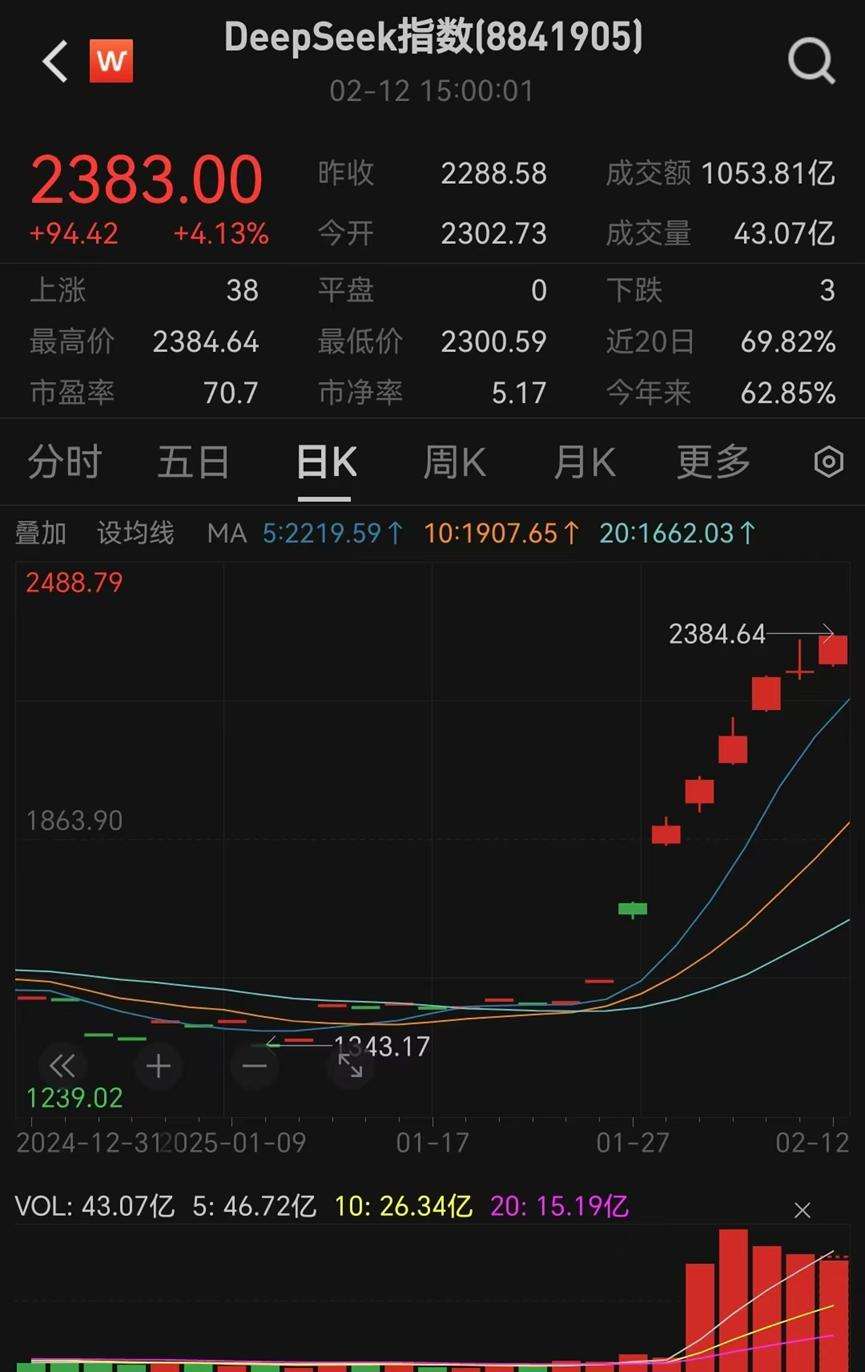
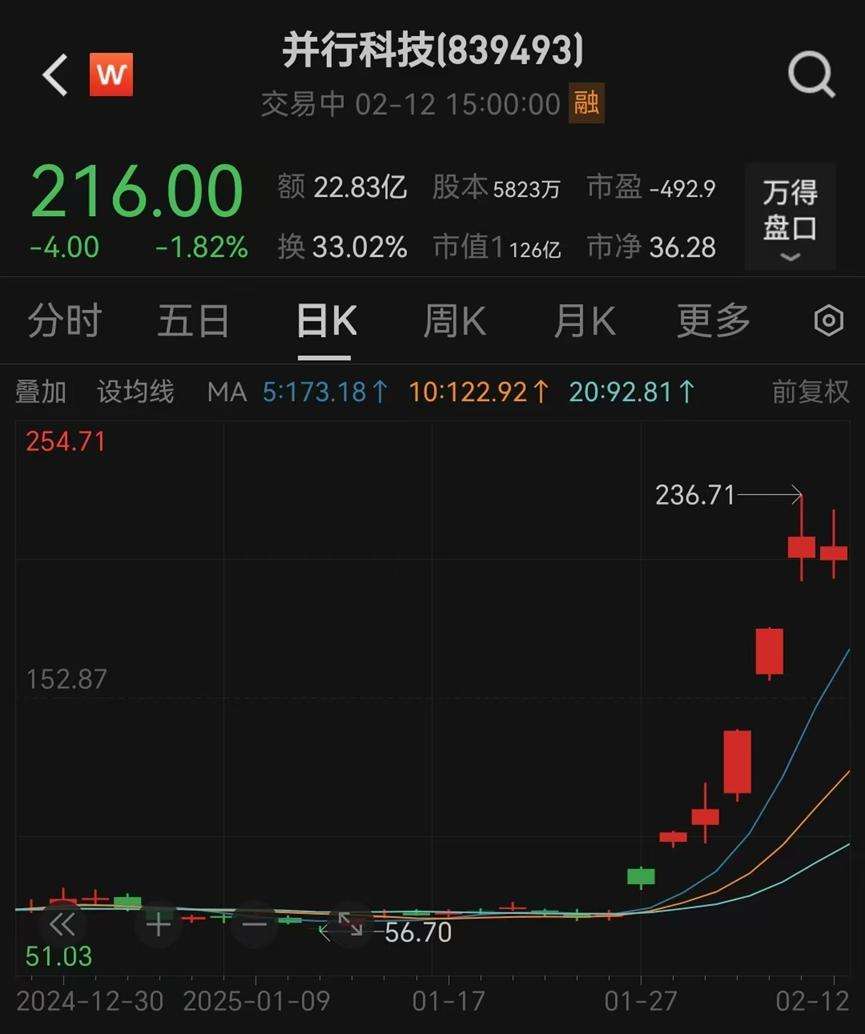
近日,AI大模型公司DeepSeek的出现引发全球震动。2025年1月27日至2月12日,WindDeepSeek指数在短短7个交易日内暴涨58.29%,相关概念股并行科技同期更是飙升234.73%。其崛起不仅震撼美国,致使英伟达股价单日暴跌17%,更是在全球范围内掀起波澜。
中国工程院院士李国杰表示,DeepSeek的诞生堪称世界第三波人工智能浪潮中的标志性事件,可与2023年OpenAI发布chatgpt3.5相媲美。特别是其推出的V3和R1模型,实现了技术与发展模式的双重突破。
DeepSeek在模型算法层面创新显著。它采用新的混合专家架构(MoE),每一层设置256个路由专家和1个共享专家,前向传播时仅激活部分专家计算,大大降低了训练成本,如671B参数的DeepSeek-V3模型,函数调用和传递仅用约37B参数。同时,低秩注意力机制这一创新,对注意力机制矩阵进行压缩,将显存占用降至其他大模型的5%- 13% ,显著提升了运行效率。
推理层面,DeepSeek同样成果斐然。它通过开源公开低成本推理的奥秘,为行业发展开辟新径。并且,其采用全自动强化学习替代传统方式,提高了强化学习效率。
在全球影响力方面,DeepSeek表现惊人。2025年1月20日DeepSeek-R1发布上线,无广告投放情况下,7天内用户增长超1亿,创造新纪录,在苹果应用商店下载量在多个国家/地区位居榜首,GitHub星数也超越OpenAI。微软、AWS、英伟达等全球龙头企业纷纷在其AI服务平台部署DeepSeek-R1模型。
李国杰认为,DeepSeek闯出了人工智能发展的新路,使中国从“追赶者”转变为“规则改写者”。它打破了“高算力和高投入是发展人工智能唯一途径”的迷信,推动行业进入以算法和模型架构优化为主,兼顾数据质量与规模、理性提升算力的新阶段。其开源战略更为AI发展带来新的可能,引领行业新潮流。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号