近期,DeepSeek成为AI领域的焦点。其V3和R1模型表现出色,在大模型评测排行榜上名列前茅,相关客户端产品免费可用且备受欢迎。2025年1月,DeepSeek引发诸多关注,微软CEO盛赞,其登顶美国AppStore榜首,还导致英伟达股票狂跌,Meta加速研发LLaMA 4。这一系列事件,标志着DeepSeek在AI行业的崛起。
DeepSeek的诞生与创始人梁文锋紧密相关。他毕业于浙江大学,从量化交易起步,历经创业波折,于2023年创立杭州深度求索人工智能基础技术研究有限公司,即DeepSeek。公司发展过程中,积累了大量GPU,为模型研发奠定基础。
在技术上,DeepSeek V2通过MoE和MLA实现成本突破。MoE构建“专家系统”,优化ScalingLaw,降低计算资源;MLA融合多种内容素材,通过渐进式训练三步法提升效果、降低成本,二者融合还提出创新策略,在工程实践中表现出色。
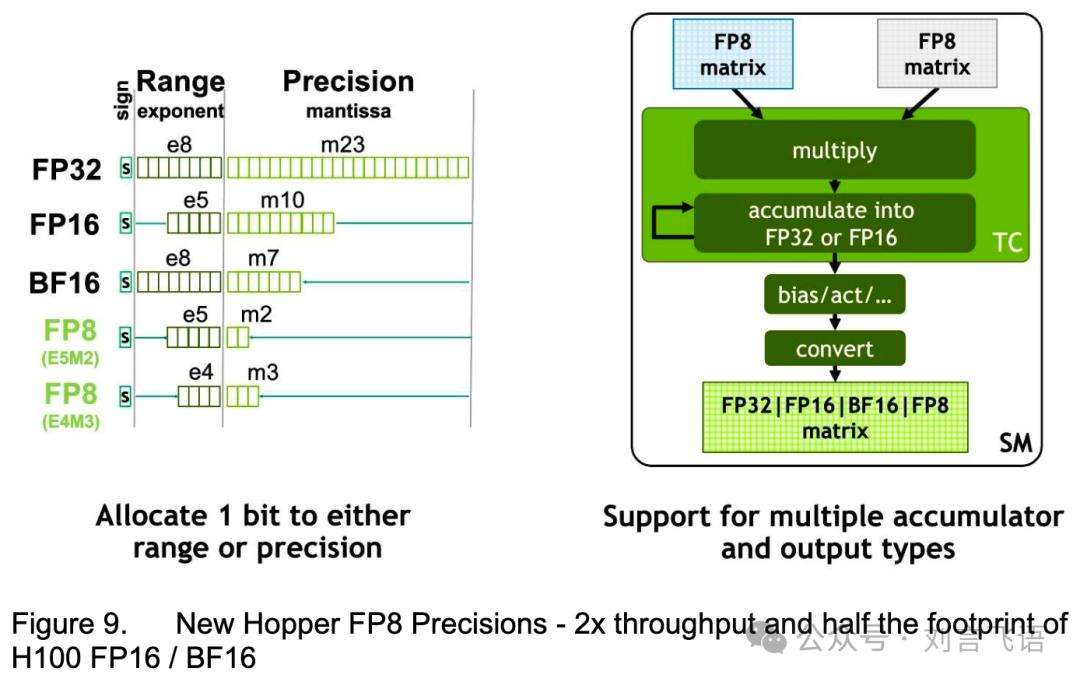
V3则凭借FP8和MTP进一步优化成本。FP8实现低精度训练,在英伟达新架构上,用一半成本达到相近性能;MTP拉长预测范围,使输出文本更具逻辑。V3训练成本公开,仅需279万GPU小时,约557.6万美元,远低于其他主流模型。
成本突破给行业带来巨大震荡。各大巨头重新规划AI投入,端侧模型发展可期,苹果等公司或受益,国产芯片也因支持DeepSeek迎来发展机遇。同时,DeepSeek调用成本低,推动人工智能行业繁荣。
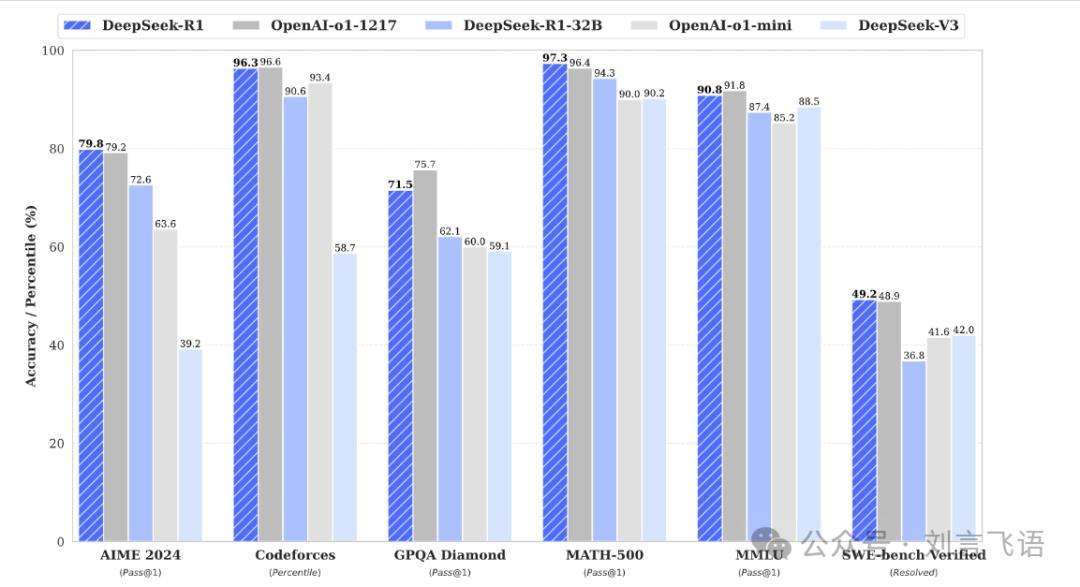
R1作为推理模型,让DeepSeek更受关注。它在推理评测中表现出色,达到甚至超越OpenAI的o1模型。R1-Zero采用纯强化学习,摒弃传统指导方式,通过独特训练方法和奖励模型,实现自主学习,给行业带来新路径。
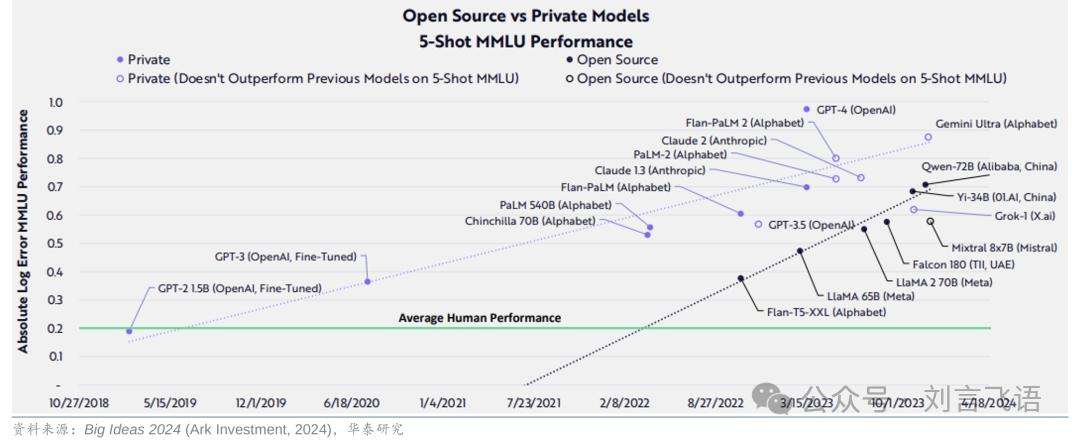
DeepSeek在开放方面也走在前列。它开放权重,许可证模式为MIT,几乎最开放,推动AI领域开源发展,其开源社区发展迅速,吸引众多开发者,也获得英伟达等厂商支持。
尽管成就显著,DeepSeek也面临一些问题。如R1存在性能不足、语言混乱等问题,蒸馏技术引发争议,虽属行业共识,但涉及知识产权等问题。
展望未来,DeepSeek在中美AI竞争中面临挑战与机遇,科技生态将因之丰富,能源结构或受影响,通往AGI的道路也更加清晰。其成功源于对好奇心的坚持,也激发了创新信心,为行业树立榜样。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号