近期,一项多机构联合研究在AI领域引发关注。研究聚焦于测试时扩展(TTS)这一提升大模型性能的新范式,探讨如何在不同条件下最优地扩展测试时计算。
研究人员重新思考了“计算最优”的测试时Scaling。计算最优的测试时Scaling旨在为每个问题分配最优计算资源。从强化学习角度看,以往的方法可分为获得在线PRM和离线PRM两种。在线PRM能产生更准确奖励,但为每个策略模型训练用于防止OOD问题的PRM计算成本高。因此,研究人员在更一般设置下研究,提出奖励应整合到计算最优的TTS策略中,这为实际TTS提供了更普适框架。
在衡量问题难度方面,团队发现使用MATH的难度等级或基于Pass@1准确率分位数的oracle标签无效,因为不同策略模型推理能力不同。于是选择使用绝对阈值,基于Pass@1准确率定义了简单、中等和困难三个难度等级。
关于如何最优地Scaling测试时计算,研究针对多个问题展开实验。对于不同策略模型和PRM对TTS的影响,实验发现PRM在不同策略模型和任务间的泛化能力是挑战,TTS性能与PRM的过程监督能力正相关,且最优TTS方法依赖于策略模型大小。
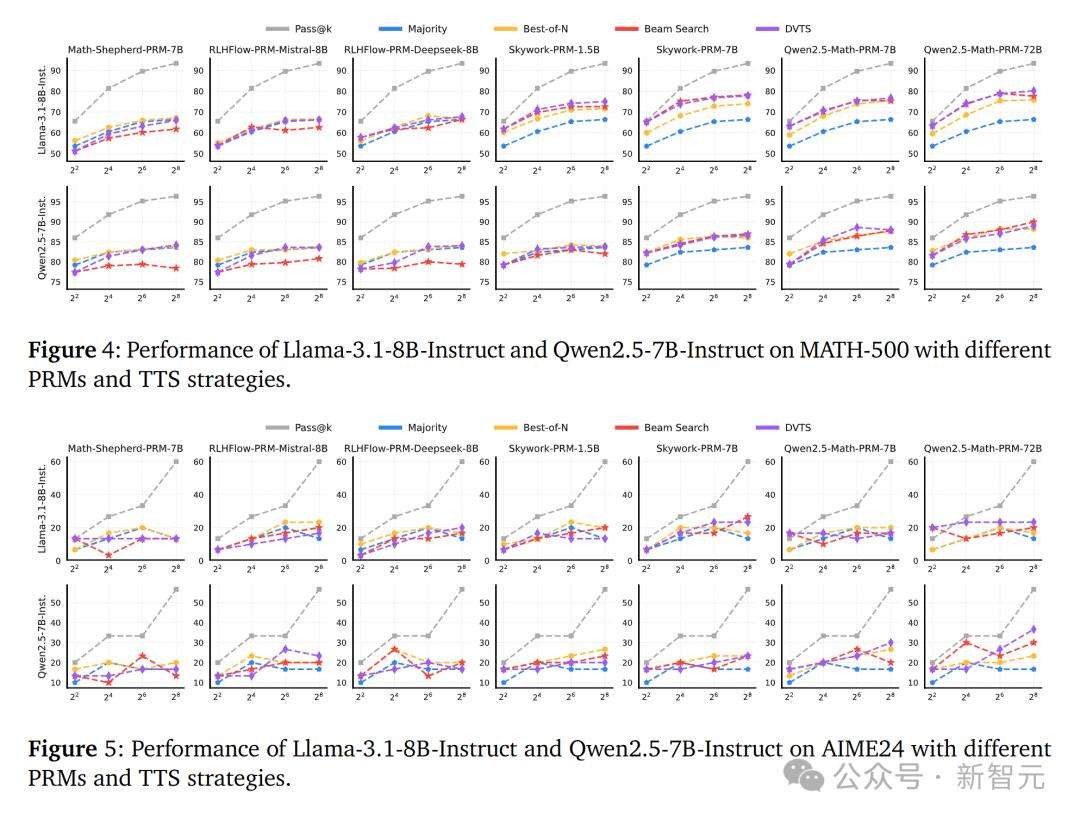
TTS在不同难度问题上的改进情况表明,最优TTS方法随难度级别和策略模型参数范围而变化。如小规模策略模型在简单问题上BoN更优,较难问题上束搜索更好;不同参数范围的策略模型有各自适合不同难度问题的方法。
研究还发现PRM对步骤长度存在偏差,这与训练数据有关,且PRM对投票方法具有敏感性,PRM的训练数据对提升其在搜索过程中发现错误的能力至关重要。
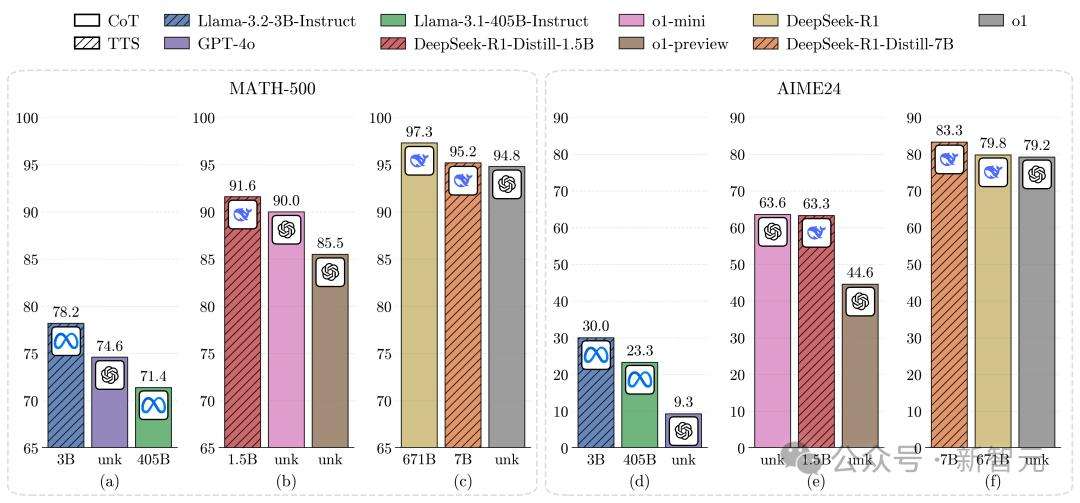
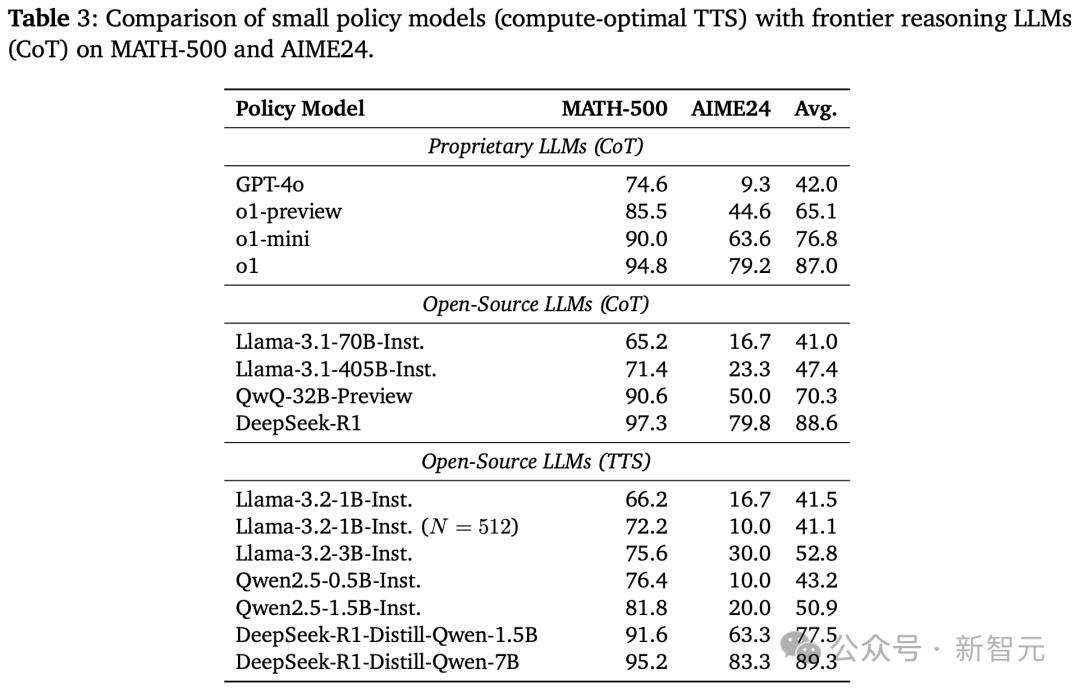
在计算最优TTS策略下,研究人员进一步实验评估。结果显示,较小的策略模型能在计算最优TTS策略下优于较大模型,计算最优TTS比多数投票效率高256倍,相比CoT提升了154.6%的推理性能,且TTS比直接在MCTS生成数据上应用RL或SFT的方法更有效,但在复杂任务上效果稍逊。
此项研究由来自清华、哈工大、北邮等机构的人员完成,第一作者RunzeLiu来自清华大学深圳国际研究生院,其研究重点是大模型和强化学习。研究为提升大模型推理能力提供了新方向,展示了计算最优TTS策略在模型性能提升上的潜力。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号