DeepSeek-R1在海内外引发热潮,然而其推理服务器问题与高昂成本令中小团队为难。市面上“本地部署”方案多为蒸馏版,因671B参数的MoE架构对显存要求高,在本地小规模硬件运行真正的DeepSeek-R1曾被视为不可能。
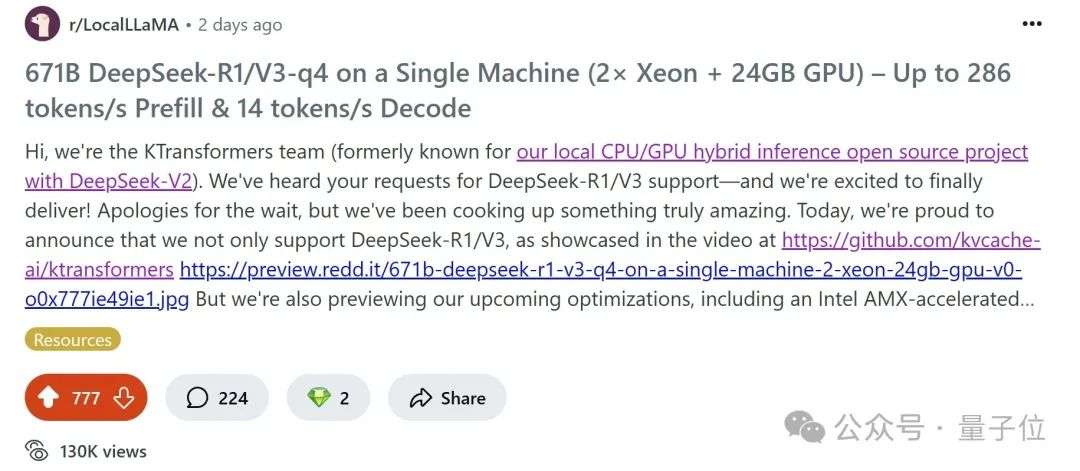
近期,清华大学KVCache.AI团队联合趋境科技的KTransformers开源项目有重大更新。它支持24G显存在本地运行DeepSeek-R1、V3的671B满血版,预处理速度最高达286tokens/s,推理生成速度最高能到14 tokens/s。
早在DeepSeek-V2时代,KTransformers就因“专家卸载”技术受关注,它让236B大模型在24GB显存消费级显卡上流畅运行,降低显存需求。随着DeepSeek-R1发布,社区需求激增,版本更新后开发者实测,实现了千亿级模型“家庭化”。
KTransformers团队还公布v0.3预览版性能指标,整合Intel AMX指令集后,CPU预填充速度最高至286tokens/s,比LLaMA.cpp快近28倍,释放了CPU算力潜能。此外,它提供兼容APi与Web界面,降低上手难度,还有灵活的“模板注入框架”。目前在localLLaMa社区热度很高。
在技术方面,KTransformers利用MoE架构稀疏性,采用GPU/CPU异构计算划分策略,将不同部分矩阵分别放在CPU/DRAM和GPU上处理,提升推理性能。在推理框架中,通过调整矩阵计算方式,发挥MLA算子性能,减少KV缓存大小,提高GPU计算利用率。
团队还引入高性能CPU和GPU算子,CPU算子用llamafile等组成框架并优化,GPU算子采用Marlin算子提高计算效率。同时对CUDAGraph改进优化,减少CPU/GPU通讯断点。此外,KTransformers是灵活的推理实验平台,能兼容多种MoE模型和算子,支持多平台。
GitHub 地址:https://github.com/kvcache-ai/ktransformers,具体技术细节指路:https://zhuanlan.zhihu.com/p/714877271



 鄂公网安备42010402001699号
鄂公网安备42010402001699号