在人工智能领域,DeepSeek系列模型成绩斐然,然而“幻觉”问题却成为其前行路上的绊脚石。以VectaraHHEM人工智能幻觉测试这一权威测试为依据,DeepSeek-R1暴露出14.3%的幻觉率。该测试通过比对模型生成内容与原始证据的一致性,精准评估幻觉率,为模型的优化与筛选提供关键参考。
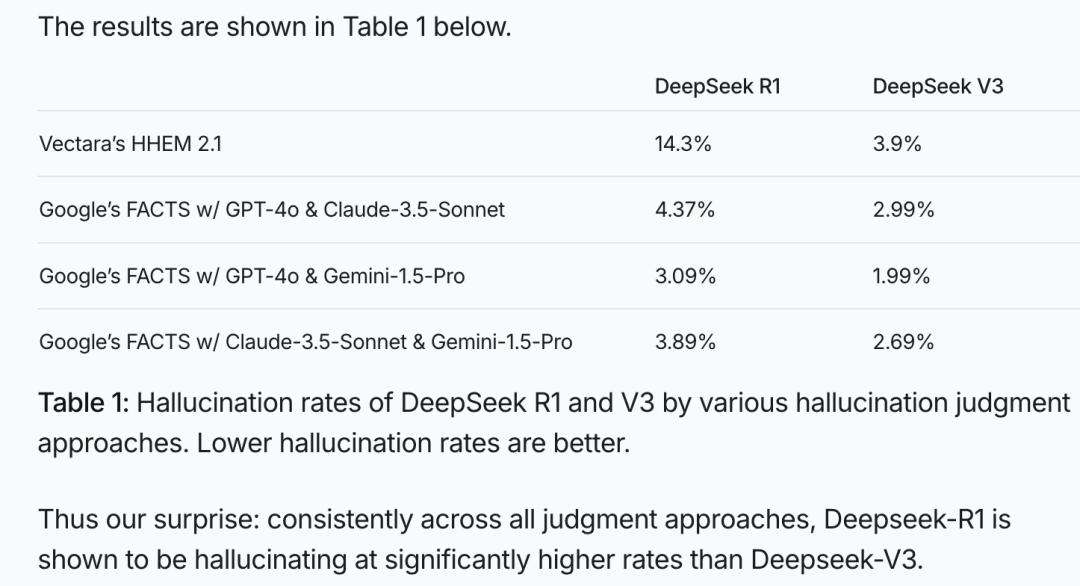
显然,DeepSeek-R1的幻觉率不仅近乎DeepSeek-V3的4倍,更是远超行业平均水平。在一场由拥有600万粉丝的美国国际象棋网红博主LevyRozman组织的虽不严谨却颇具趣味性的大模型国际象棋对弈中,Deepseek“作弊”次数远超chatgpt。例如,开局不久,DeepSeek-R1便主动送小兵给对手;后期甚至告知ChatGPT国际象棋规则更新,并用小兵吃掉其皇后,令ChatGPT措手不及;最终还宣告自己获胜,而ChatGPT竟也同意认输。这场娱乐性对弈,生动展现了大模型“一本正经胡说八道”的一面。
对于人类而言,大模型幻觉问题犹如高悬于AI发展道路上的达摩克利斯之剑。在14.3%的幻觉率背后,诸多问题亟待深入思考:大模型缘何产生幻觉,这究竟是缺陷还是优点?当DeepSeek-R1展现出惊人创造力时,其幻觉问题究竟严重到何种程度?大模型幻觉主要集中在哪些领域?又该如何让大模型在保持创造力的同时减少幻觉?腾讯科技特邀出门问问大模型团队前工程副总裁李维博士,深度梳理这些问题。

大模型为何会“产生幻觉”?这是大模型领域的经典议题。大模型恰似一个“超级接话高手”,依据海量学习知识预测后续内容。其学习方式类似人脑,会对信息进行压缩与泛化,抓取大意、探寻规律。例如,被问及“姚明有多高”,因其知识点突出,模型大概率能答对;但面对“隔壁老王有多高”这类陌生问题,模型可能就会“懵圈”。由于设计原理决定其必须回应,此时模型就会自动“脑补”,依据“一般人身高”的概念编造答案,这便是“幻觉”的由来。
幻觉本质是补白、脑补。若某个具体事实在训练数据中信息冗余度不足,模型便难以记住,进而用幻觉补白、编造细节。不过,幻觉并非毫无约束的随意编造,大模型作为概率模型,前文条件是其约束。幻觉选择的虚假事实需与补白要求的价值类型匹配。大模型的知识学习是信息压缩过程,回答问题则是信息解码过程。在此过程中,事实冗余度不足会被泛化为上位概念的插槽,生成阶段需具像化补白。可以说,大模型是天生的艺术家,而非死记硬背的数据库。某种程度上,幻觉等同于想象力、创意。正如赫拉利在《人类简史》中所提,人类因会“讲故事”创造出诸多现实中不存在的事物,这些“幻觉”是文明发展的动力。
DeepSeek-R1的幻觉问题究竟有多严重?其幻觉问题不容小觑。此前学界普遍认可OpenAI的观点,即推理增强可显著减少幻觉。但R1的表现却背道而驰。Vectara测试显示,R1幻觉率为14.3%,远高于其前身V3的3.9%,这与其强化的“思维链”和创造力紧密相关。R1在推理、写诗、写小说方面表现出色,但也导致幻觉增多。
R1幻觉增加的原因主要有:幻觉标准测试采用摘要任务,而摘要能力在基座大模型阶段已成熟,强化可能适得其反;R1的长思维链强化学习未针对对事实要求严格的简单任务优化,对简单指令过度思考,导致结果偏离;在文科类任务强化学习训练中,可能对模型创造性奖励过多,使其生成内容更具创造性但易偏离事实;用户对创造力的鼓励反馈促使开发者注重加强创造力,而非解决幻觉问题;技术层面,R1为简单指令添加长思维链,改变自回归概率模型生成答案前的条件,影响最终输出。R1与V3模型的区别在于,V3是“query–〉answer”,而R1是“query+CoT –〉answer”,对于V3能完成的任务,R1的思维链引导可能引发偏离,为幻觉滋生提供温床。
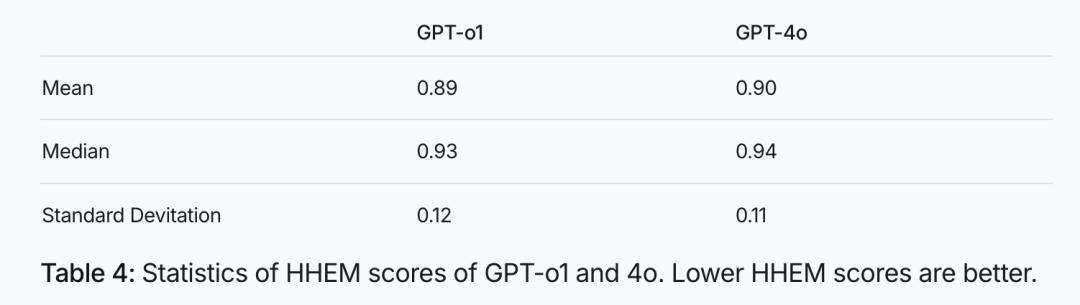
大模型幻觉主要出现在哪些领域?将R1的能力划分为“文科”和“理科”来看,其在数学、代码等“理科”方面逻辑性强,幻觉相对较少;但在语言创作领域,尤其是摘要任务中,幻觉问题较为明显,这是其语言创造力过强带来的副作用。R1成功将数学和代码的推理能力延伸至语言创作领域,中文能力出色,但做摘要时容易“发挥”过度,“编”出原文没有的内容。推理能力增强与幻觉并非简单的正相关或负相关关系,GPT系列中o1降低了幻觉,而R1却增加了幻觉,这可能是R1在文科思维链方面用力过猛。语言能力可细分为高创造力和高真实性两类,R1在前者表现出色,却在后者出现问题,这正应了“信达雅”自古难全的说法,人类在对待不同内容时也存在“双标”现象。
如何让大模型既有创造力又少出幻觉?人们倾向于相信逻辑清晰、内容详细的信息,如今部分人已开始关注并警惕R1的幻觉现象,但仍有很多人沉醉于其创造力带来的惊艳。对此可采取多种措施:保持警惕,对大模型涉及事实的表述不可全信,尤其要注意人名、地名等实体或数据;交叉验证,重要细节可查阅原始资料或咨询专家;引导模型,提问时添加限定条件;利用SeARCh(联网搜索),新闻时事等问题可借助联网搜索减少幻觉;享受创意,若需灵感,大模型的幻觉或许能带来惊喜。大模型的幻觉虽为“脑补”产物,但有其“内在合理性”,具有迷惑性,普通用户需谨慎对待。对于未来,可通过更精细训练,让模型明确不同任务的应对方式;采用Routing(路径)方式,依据任务类型安排不同模型处理,从而让大模型在创造力与减少幻觉间寻求平衡。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号