近日,语音识别领域迎来重要进展,小红书的FireRed团队推出全新开源语音识别模型FireRedASR。这一基于大模型的成果,在多个标准测试集中成绩斐然,堪称中文语音识别技术的重大突破。
衡量FireRedASR的关键指标是字错误率(CER),此指标数值越低,模型识别效果越佳。在近期公开测试里,FireRedASR的CER达到3.05%,相较于此前最佳模型Seed-ASR降低8.4%,彰显了FireRed团队在语音识别技术上的创新实力。
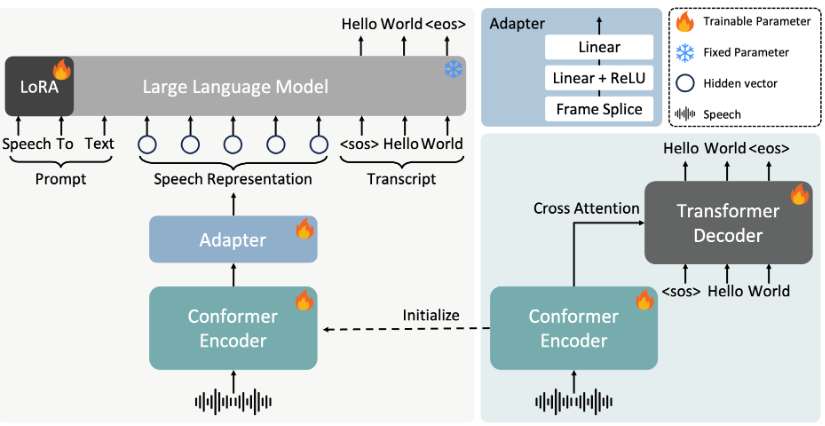
FireRedASR模型包含两种核心结构,即FireRedASR-LLM与FireRedASR-AED。前者聚焦于极致的语音识别精度,后者则巧妙平衡了准确率与推理效率。团队还提供不同规模模型及推理代码,满足各类应用场景需求。
在众多日常应用场景中,FireRedASR展现强大性能。在短视频、直播和语音输入等组成的测试集中,FireRedASR-LLM的CER较业内领先服务提供商降低23.7%至40%。在歌词识别场景中表现更为突出,CER实现50.2%至66.7%的相对降低。
此外,在中文方言和英语场景里,FireRedASR同样表现出色。其在KeSpeech和LibriSpeech测试集上的CER显著优于以往开源模型,证实了在多种语言环境中的鲁棒性与适应性。
FireRed团队开源这一模型,旨在推动语音识别技术发展与应用。所有模型和代码已在GitHub公开,诚邀更多开发者和研究者参与其中。HuggingFace链接:https://huggingface.co/FireRedTeam,github链接:https://github.com/FireRedTeam/FireRedASR 。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号