ScreenAI:视觉语言模型的新里程碑
由谷歌研究团队研发的ScreenAI是一款先进的可视屏幕AI模型,它专注于解析和操作用户界面(UI)以及信息图表。ScreenAI借助PaLI架构,结合了视觉和语言处理的强大功能,并借助Pix2Struct的模式拼接技术,赋予其实时理解及生成屏幕UI相关文本的能力,如回答用户问题、导航操作和内容摘录。
为了更好的理解ScreenAI的工作,以下是一个形象的视觉辅助:

如果您对研究论文感兴趣,可以查看arXiv上的公开文献:ScreenAI: Understanding and Interacting with Screen Content。此外,对于想要实际操作该模型的开发者,可以在GitHub上找到其PyTorch实现:ScreenAI PyTorch Implementation。
主要功能概览
ScreenAI的核心功能包括但不限于以下几个方面:
- 屏幕信息识别:识别和理解屏幕上UI的各个元素,包括它们的类型、所在位置及其相互联系。
- 问题解答:ScreenAI基于视觉信息提供准确的问答服务,帮助用户获得所需信息。
- 导航指导:解释并执行导航指令,实现对用户界面的流畅交互。
- 内容摘要:对屏幕信息进行精简总结,提炼关键信息。
- 自适应屏幕:无论屏幕尺寸和分辨率如何,ScreenAI都能够适应,确保在多种设备上的兼容性。
技术支持与架构
下面是一个关于ScreenAI技术原理的图示:
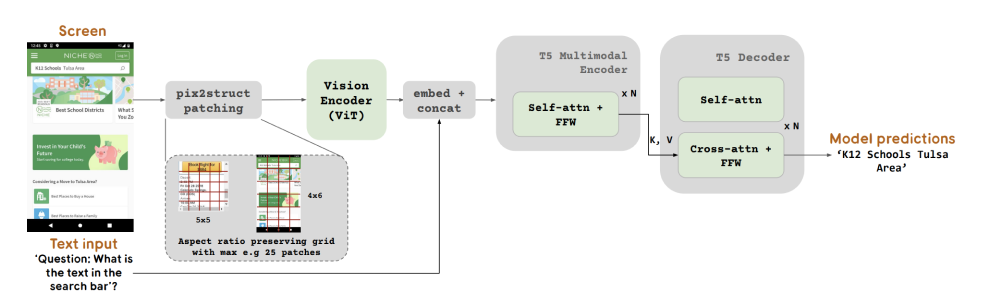
- 多模态编码器:基于PaLI架构,由视觉编码器和语言编码器组成,负责将视觉和文本信息转换为嵌入模型。
- 图像与文本融合:将视觉和文本嵌入融合,为模型提供多维度信息,以处理更复杂的视觉语言任务。
- 自回归解码器:利用T5解码器生成文本输出,根据视觉输入生成自然语言响应。
- 自动数据技术:通过PaLM 2-S模型自动生成合成训练数据,去除手动标注的繁琐。
- 图像分割技术:采用Pix2Struct技术,适应不同尺寸的屏幕截图。
- 模型训练与配置:提供不同规模的模型变体,从小型的670M到大型的2B和5B模型参数,预训练和微调结合,以应对多样化的训练任务。
ScreenAI的开发不仅为AI视觉语言理解领域带来了新的突破,也为未来在自动化界面设计和用户体验提升方面的研究开辟了新的道路。随着技术的不断发展,我们可以预见ScreenAI在智能设备以及交互应用中的广阔应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号