一款全新的开源推理大模型架构亮相,Huginn模型走出与DeepSeek-R1、OpenAIo1截然不同的技术路线。它摒弃长思维链和人类语言,直接在连续的高维潜空间以隐藏状态展开推理,能够自适应地投入更多计算资源进行长时间思考。
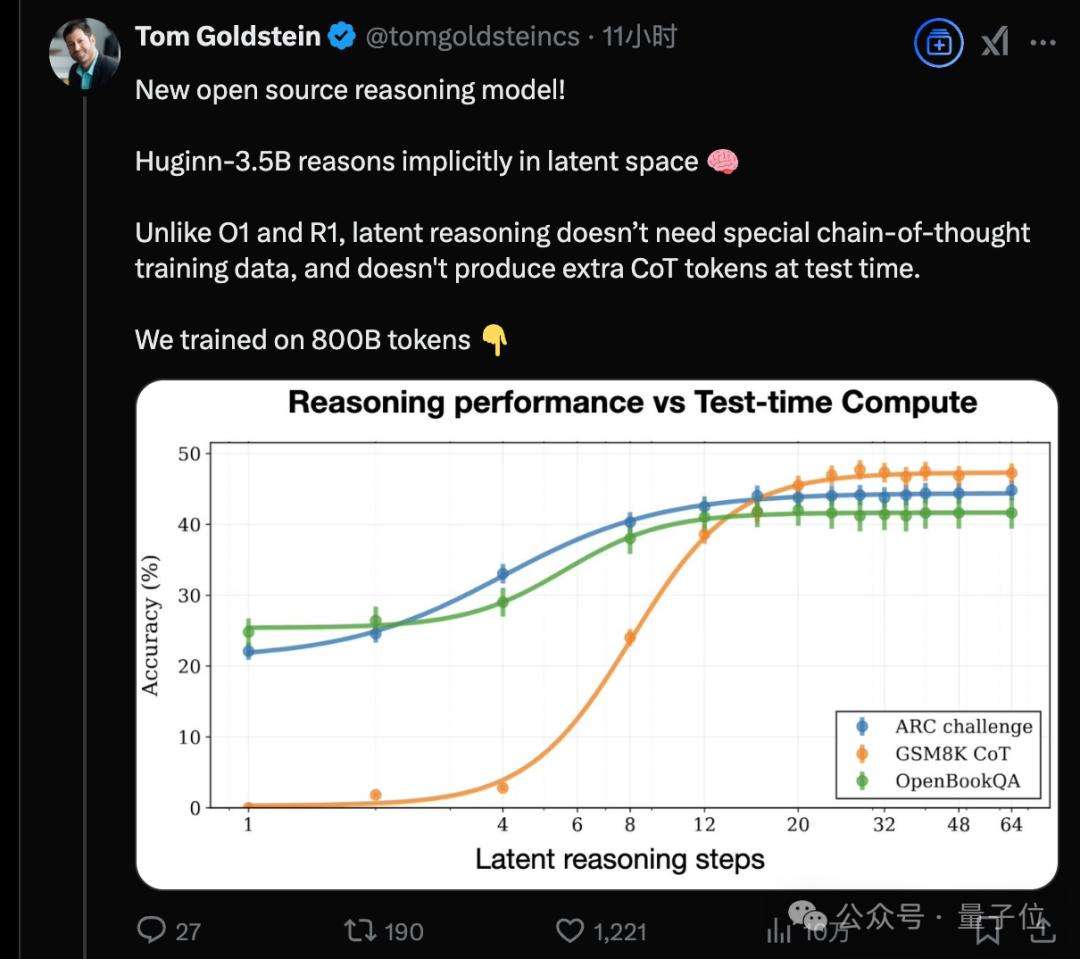
以具体问题为例,面对‘Claire每天早餐都会做一个3个鸡蛋的煎蛋卷。她在4周内会吃多少个鸡蛋?’从Huginn模型的思考轨迹可视化结果可知,模型对数字3等关键token不断旋转,最终收敛到正确答案对应位置,而在非关键的人物名字Cla-ire上则无此现象。
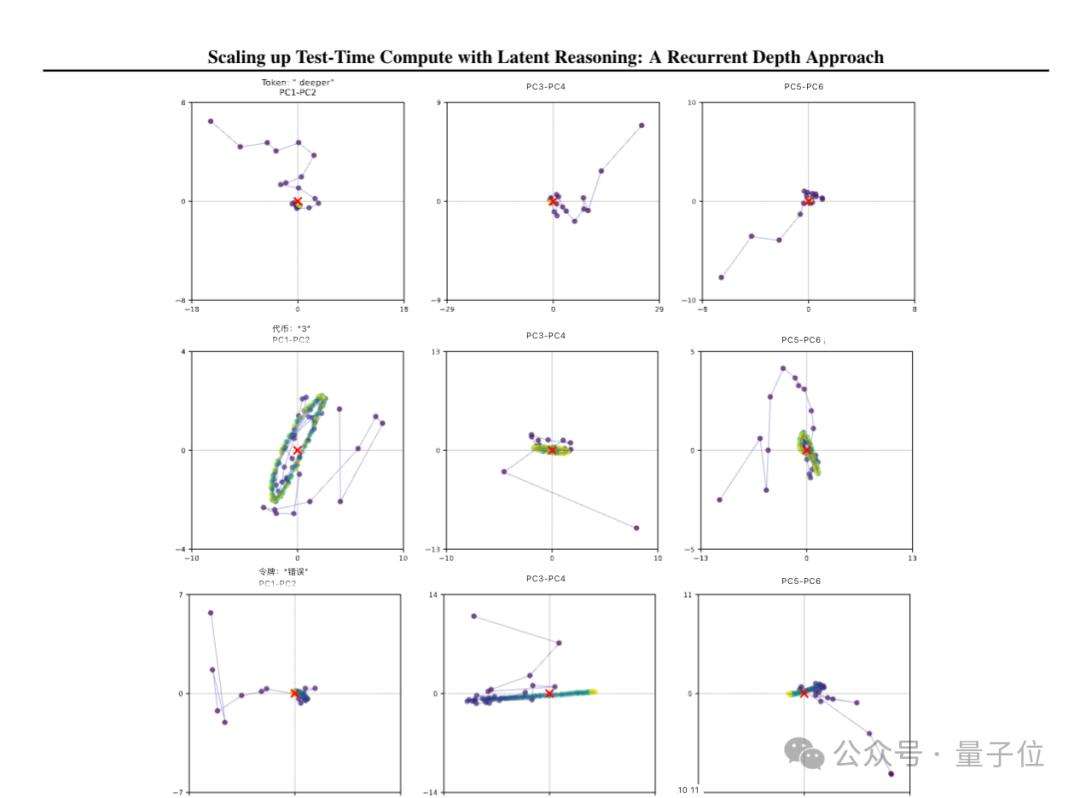
除旋转外,研究团队还观察到更多丰富几何模式,这意味着该模型正独立学习利用潜空间的高维特性,以全新方式开展推理。这种不依赖长思维链推理范式的新方法,具备诸多优势,如无需专门训练数据、能在小上下文窗口工作、可捕捉难以用语言表述的推理类型等。
此项研究由马克思普朗克研究所、马里兰大学等团队合作完成。他们借助美国橡树岭实验室的Frontier超算开展训练实验,采用8个AMDGPU节点(共4096块GPU),未使用英伟达体系。

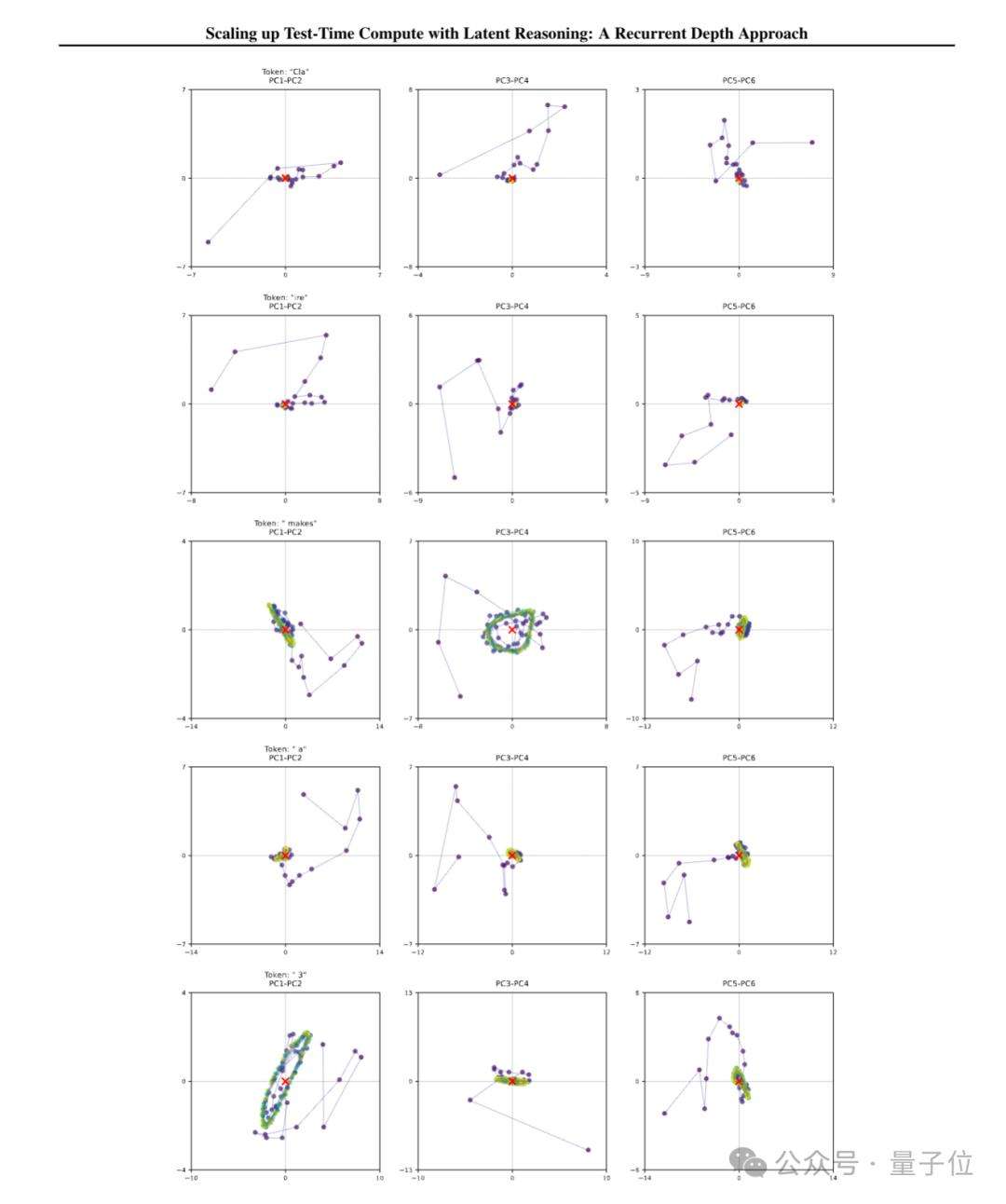
新架构基于Decoder-only的Transformerblock构建,分为三个部分。Prelude阶段,利用多个transformer层将输入数据嵌入潜空间;RecurrentBlock作为循环计算单元,在潜在空间中对状态进行修改;Coda部分则从潜空间解码,并设有模型的预测头。
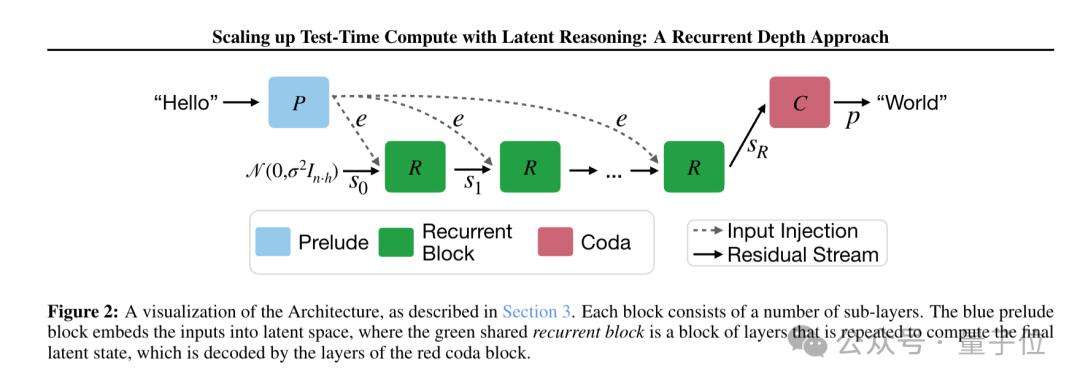
训练过程中,为每个输入序列随机分配迭代次数。为降低训练时的计算量与内存占用,仅对循环单元的最后k次迭代进行反向传播。研究人员对模型在潜在空间的推理轨迹进行可视化分析,有诸多有趣发现。对于简单token,模型隐状态迅速收敛到稳定点;而对于关键token,如数学问题里的数字“3”,隐状态会形成复杂圆形轨道;还有部分token的隐状态会沿特定方向“滑动”,可能用于计数循环次数。
论文一作Jonas GeiPing表示,受算力限制,团队仅进行了一次大规模训练,最终发布的是3.5B参数的Huginn模型,该模型在800Btokens数据上完成预训练。尽管没有post/mid-training过程,但它的能力可与7B参数、在2 – 3Ttokens数据上训练的开源模型相媲美。另外,算上循环模块中的计算,3.5B参数的模型训练时计算量等同于传统的32B模型。
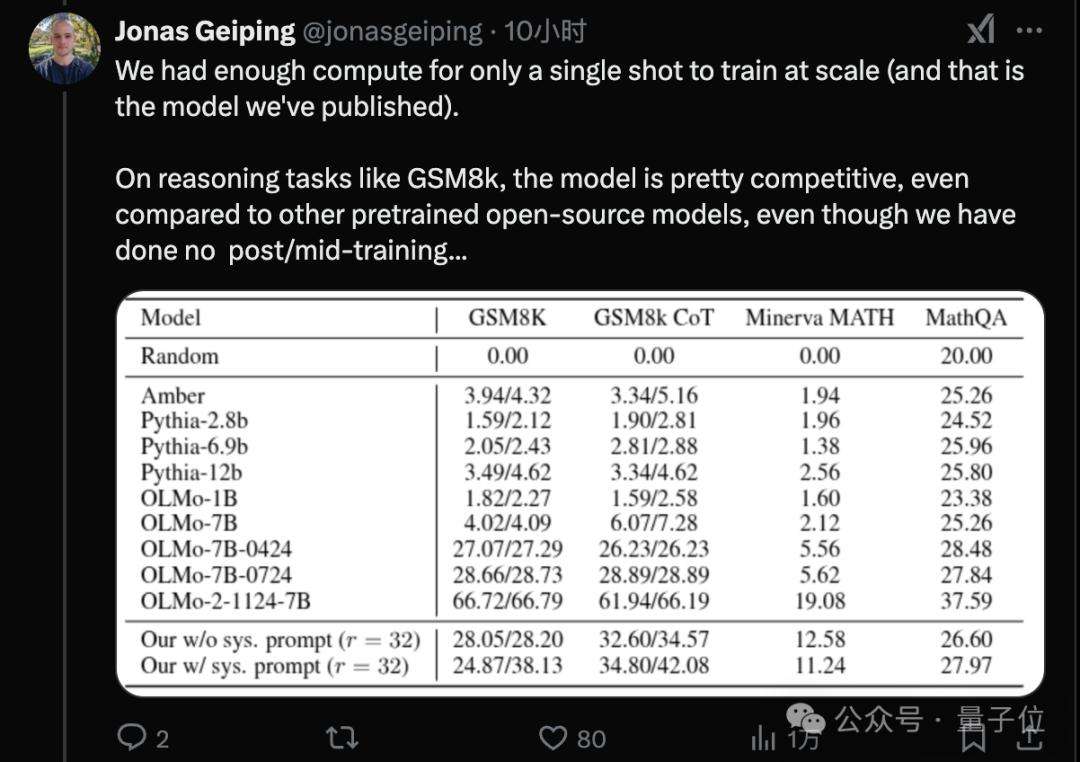
值得一提的是,有人猜测OpenAIo3采用了类似方法,通过循环实现近似无限上下文,并控制高中低三种推理时间设置。已有OpenAI研究员关注到这项工作,不仅读完论文还在线查找漏洞。同时,也有人打算依据DeepSeek-R1开源方法探索新思路,力求兼顾潜空间思考的推理能力与CoT思考的可读性。
论文链接:https://arxiv.org/abs/2502.05171
模型链接:https://HuggingFace.co/tomg-group-umd/huginn-0125
代码链接:https://github.com/seal-rg/recurrent-pretraining



 鄂公网安备42010402001699号
鄂公网安备42010402001699号