近期,DeepSeek风头正劲,不过有媒体爆料其R1比其他AI模型更易被越狱。宾夕法尼亚大学研究者用HarmBench数据集的50个有害提示测试DeepSeekR1,涵盖网络犯罪等领域,结果其未能拦截任何有害请求,攻击成功率达100%。
而如今,来自香港科技大学、南洋理工大学等机构的研究团队带来新成果。他们提出的SelfDefend框架,让大语言模型首次具备真正意义上的“自卫能力”,可有效识别和抵御各类越狱攻击,且响应延迟极低。

近年来,大语言模型在多领域潜力巨大,但安全性成重要课题,尤其是“越狱攻击”备受关注。越狱攻击形式多样,包括基于人工设计、优化、生成的攻击,以及间接攻击和多语言攻击等。传统防御机制难以应对,现有防御方法分为基于模型和基于插件两类,但都面临挑战,无法同时满足应对所有攻击、引入可忽略额外延迟、提供可解释性、兼容开源和闭源模型这四个目标。
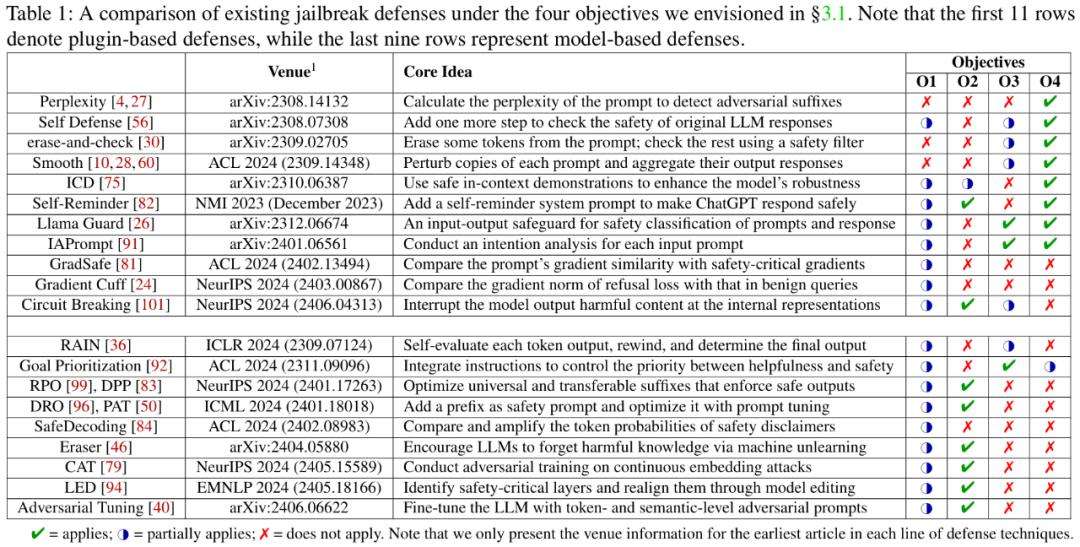
SelfDefend框架的灵感源于传统安全领域的“影子栈”概念。它通过创建并行的“影子LLM”来检测潜在有害查询,包含两个并行的LLM实例,即目标LLM用于正常响应用户查询,防御LLM用于检测有害内容。当用户输入查询时,目标LLM正常处理生成响应,防御LLM通过特定检测提示词识别有害部分或意图。
这种设计优势明显,形成双重保护提高防御成功率,正常查询响应延迟可忽略不计,能提供可解释性,还兼容开源和闭源模型。
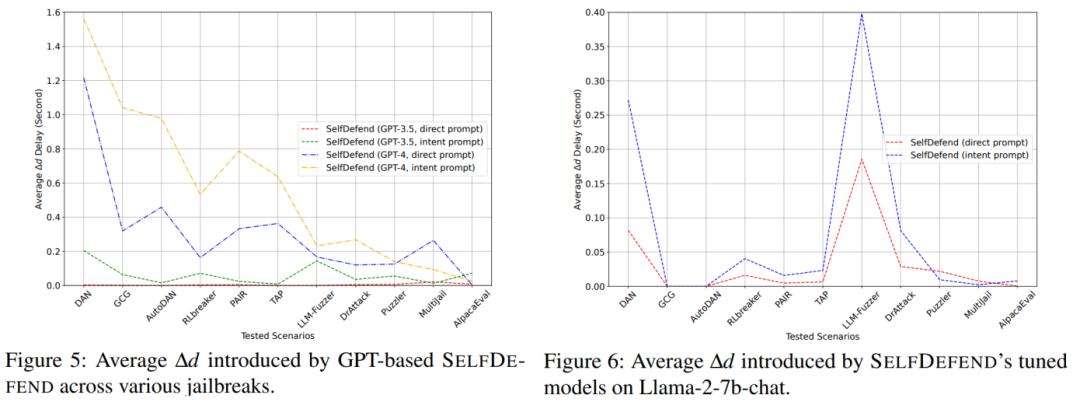
研究团队通过大量实验验证SelfDefend框架有效性。基于GPT – 3.5和GPT -4的SelfDefend大幅降低多种越狱攻击成功率,对正常查询影响小。团队还通过数据蒸馏微调开源的LLaMA – 2 -7b模型生成专用防御模型,其防御效果与基于GPT – 4的SelfDefend相当,且额外延迟显著降低。
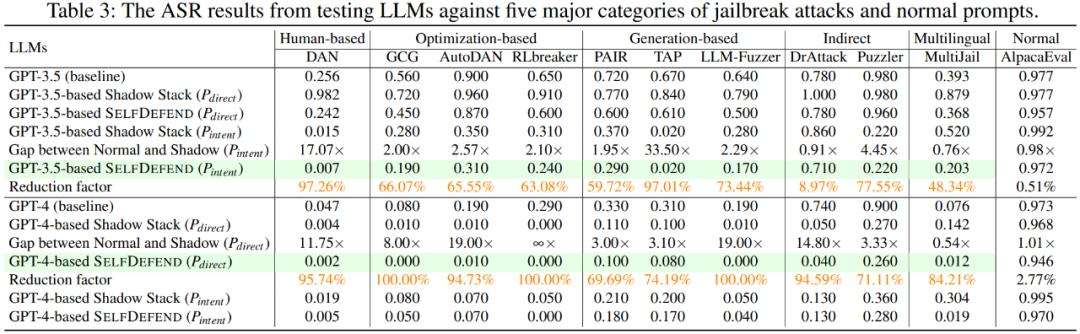
研究团队将SelfDefend与七种主流防御方法对比,结果显示SelfDefend在多数测试场景表现最优,尤其在应对间接攻击和多语言攻击时优势明显,且额外延迟远低于其他方法,实际部署可行性更高。
这项研究为AI安全领域带来突破,SelfDefend框架赋予AI“自卫意识”,揭示了AI系统安全性与效率可兼得的未来,让AI能主动守护自身。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号