近期,谷歌DeepMind围绕DeepSeek模型成果及低成本的观点再度引发关注。2月9日,谷歌DeepMind首席执行官DemisHassabis在活动中称,DeepSeek人工智能模型“或许是我所见来自中国的最佳作品”,该模型实现了“极为出色的工程”,甚至“在地缘政治层面改变了一切”。
然而,从技术角度,Hassabis认为DeepSeek“未展示新的科学进步”。他表示,“尽管炒作热度高,但实际上并无新科学进展,使用的是已知技术,很多还是谷歌和DeepMind发明的。谷歌本周发布的gemini2.0Flash模型比DeepSeek的更有效。”此外,他还驳斥了DeepSeek颠覆人工智能开发经济学的观点,称“没看到新的神奇技术,DeepSeek在效率曲线上并非例外”。AnthroPic创始人DarioAmodei也曾表示,“DeepSeek-V3未从根本改变大模型经济模式,只是符合成本降低曲线上的预期节点,不同的是率先实现的是中国公司。”
谈到DeepSeek模型训练成本数据,Hassabis强调,DeepSeek“似乎仅报告了最后一轮训练成本,这只是总成本的一小部分”。独立研究机构SemiAnalysis也认为,当前宣传的DeepSeek成本价格“存在明显误解”,仅计入特定部分,不能反映全周期总体投入。其估算,DeepSeek单硬件支出就远超5亿美元,新架构设计、模型开发等都需大量资金。SemiAnalysis得出结论,DeepSeek论文中的557.6万美元成本仅是预训练阶段GPU直接成本,占总实现成本的一小部分,还有硬件研发等其他投入。该机构还以Claude为例,称Claude3.5 Sonnet训练成本数千万美元,若Anthropic只需此投入就能构建模型,就不会筹集大量资金。
DeepSeek在论文中对557.6万美元训练成本有明确解释,是通过算法、框架和硬件优化协同设计实现。预训练阶段,每万亿个token上训练DeepSeek-V3所需GPU小时数少,总训练成本低,且此成本仅包括官方训练,不涉及其他相关成本。对于SemiAnalysis提到的结构、算法等成本问题,论文也有说明,但未提及Hassabis“仅最后一轮训练成本”的猜测。SemiAnalysis对比OpenAI成本下降幅度证明成本下降“自然”,称算法改进使训练与推理所需算力减少,实现相同功能的模型情况不断出现。其估计算法进步速度为每年4倍,且DeepSeek率先实现强大的成本与能力组合,今年年底服务成本可能进一步降低。
DeepSeek背后是管理规模超600亿元的对冲基金幻方量化,它是在交易算法中引入AI技术的先驱之一。很早就意识到AI潜力,持续增加GPU投入,2021年在出口限制未落地时将A100GPU增加至1万张。2023年5月拆分成立“DeepSeek”,专注AI能力塑造。当时因外部投资者认为AI缺乏盈利商业模式,所以选择自筹资金。如今,幻方量化与DeepSeek大量共享算力、人力等资源。
DeepSeek已发展成紧密协同项目。据SemiAnalysis估算,其GPU总投资额超5亿美元。该机构预计DeepSeek掌握约5万张HopperGPU,拥有约1万张H800和1万张H100,还大量订购H20GPU。目前,英伟达推出多个H100版本,H20专供中国模型服务商,H800算力与H100相同但网络带宽低。过去9个月英伟达生产超百万张H20GPU,由幻方量化与DeepSeek共同使用,用于多种用途。SemiAnalysis分析认定,DeepSeek总服务器资本支出约16亿美元,集群运营成本达9.44亿美元。设备分散部署带来资源集中挑战,各AI实验室等可能需采购更多GPU,X.AI情况特殊,GPU集中在一处设施。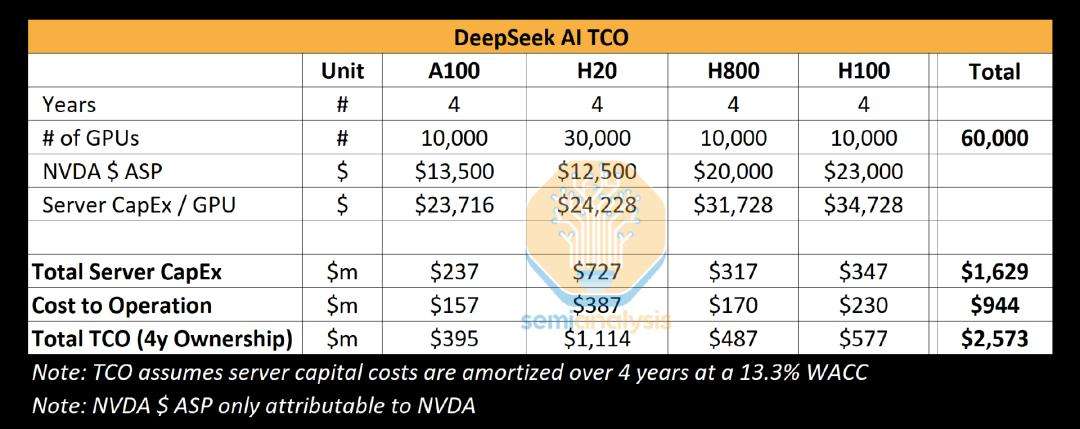
DeepSeek专门从国内招募人才,注重能力和好奇心,定期在顶尖高校举办校招活动,员工多毕业于这些大学。其工作岗位灵活,招聘广告称员工可使用多达1万张GPU,且年薪优厚,顶尖申请者年薪超130万美元。目前员工约150人且在快速扩张,招聘岗位多样,多数岗位月薪3万元起步,最高9万元,“14薪”,年薪最高达百万级别,实习生日薪500- 1000元。从工商信息看,DeepSeek部分员工可能借调于母公司幻方量化。此外,其北京办公地址租金不菲。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号