近期,DeepSeek在全球范围内引发的热潮持续升温。中国AI军团凭借大模型实现反向技术输出,DeepSeek-R1虽已开源,但训练数据等关键信息未完全公开。在此背景下,HuggingFace领衔的Open R1项目备受关注,其旨在完全开放复现DeepSeek-R1,补齐未公开技术细节。
OpenR1项目启动后进展迅速,已完成GRPO实现、训练与评估代码编写以及用于合成数据的生成器构建。如今,他们又发布了OpenR1-Math-220k数据集,填补了DeepSeekR1合成数据的空白。
DeepSeek R1能将高级推理能力迁移到较小模型,其团队生成的60万条推理数据未对其他团队开放。OpenR1-Math-220k数据集应运而生,OpenR1团队利用DeepSeek R1生成80万条推理轨迹,经筛选验证得到22万条高质量数据。这些数据可助力更小模型达到媲美DeepSeekR1的效果,例如在该数据集上训练出的Qwen-7B-Math-Instruct,性能与DeepSeek-Distill-Qwen-7B相当。
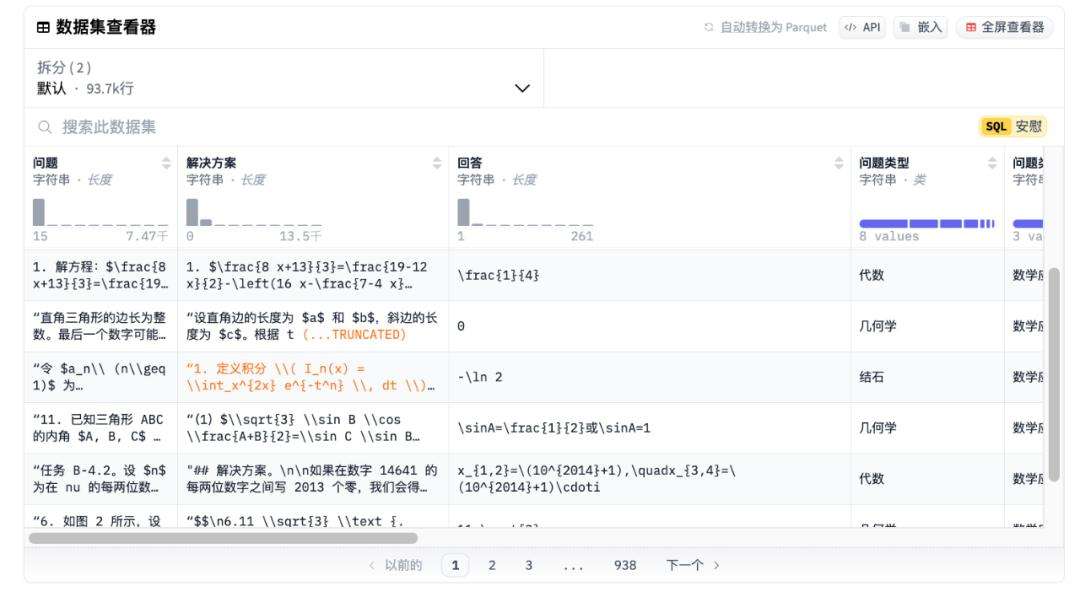
OpenR1-Math-220k数据集具有诸多独特之处。它拥有80万条R1推理轨迹,通过本地运行512个H100,基于NuminaMath1.5,实现自动过滤正确答案,保障了数据的高质量。数据集分为default和extended两部分,各有特点。
在数据生成方面,OpenR1团队让DeepSeek R1为NuminaMath1.5的40万个问题生成答案,遵循特定参数设置,限制每次生成的tokens数量。最初使用vLLM进行推理,后尝试SGLang,速度大幅提升。为提供更多灵活性,每个问题生成多个答案。
数据过滤环节,团队设计数学验证系统,改进Math-Verify工具,并借助LLaMA-3.3-70B-Instruct模型进行二次评估,找回大量被「误判」的数据。对于多个正确答案的数据行,尝试使用奖励模型筛选最佳答案,但效果未达预期。
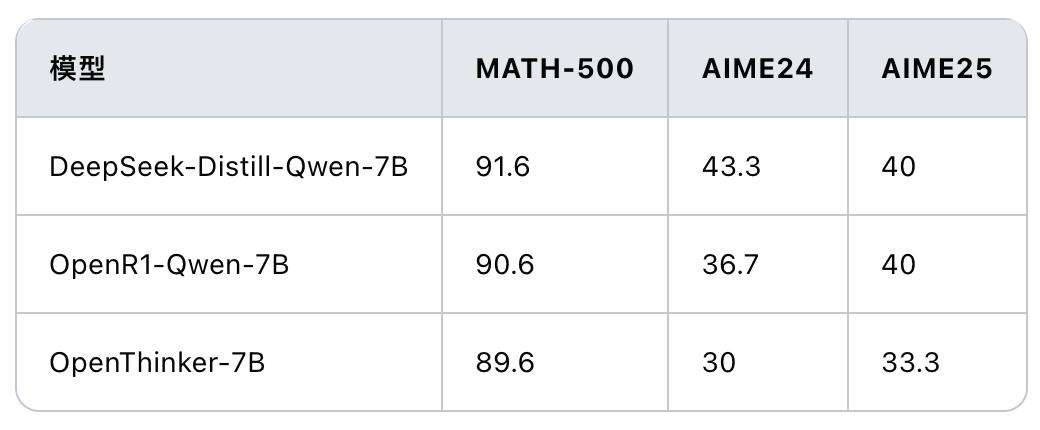
Open R1在OpenR1-Math-220k基础上对Qwen2.5-Math-Instruct进行微调,扩展上下文长度。性能对比显示,OpenR1-Qwen-7B与DeepSeek-Distill-Qwen-7B在数学成绩上差距不明显。
此外,开源社区对GRPO展开多方面探索,发现少量高质量训练样本可能引发开源模型的推理能力。同时,关于LLM推理方式、数据规模及CoT长度等问题也引发思考。OpenR1团队表示将继续实验,值得期待。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号