介绍StreamingT2V模型
PicsArt AI研究团队精心打造了一款革新性的文本到视频生成模型——StreamingT2V,该模型针对现有技术在处理长视频生成时遇到的诸多挑战,如视频质量下滑、场景切换不连贯以及视频卡顿等问题,提出了创新性的解决方案。StreamingT2V模型通过结合条件注意模块(CAM)、外观保持模块(APM)以及随机混合技术,成功实现了平滑且连贯的长视频生成,视频长度可达1200帧或更长,同时确保视频内容与文本描述高度一致。

官方网站及资源
- 项目主页:访问StreamingT2V官网了解更多详情。
- GitHub仓库:查看GitHub代码库获取模型和源码信息(即将上线)。
- 研究论文:阅读发表在arXiv上的研究论文深入了解模型原理。
StreamingT2V的关键特性
- 长视频创作:支持根据文本描述生成长视频,帧数可达80, 240, 600, 1200帧或更多,远超传统模型的生成能力。
- 帧间流畅性:生成的视频帧之间具有连贯的过渡,有效避免了长视频生成中的常见问题。
- 图像质量保障:注重每一帧图像的质量,即使视频较长,也能保证每一帧的清晰度。
- 文本与视频同步:确保生成的视频内容与用户的文本描述紧密对应。
- 视频质量提升:采用随机混合技术,在保持时间连贯性的同时提升视频的分辨率和视觉效果。
StreamingT2V的工作流程详解
StreamingT2V的工作流程主要包括以下几个关键阶段:
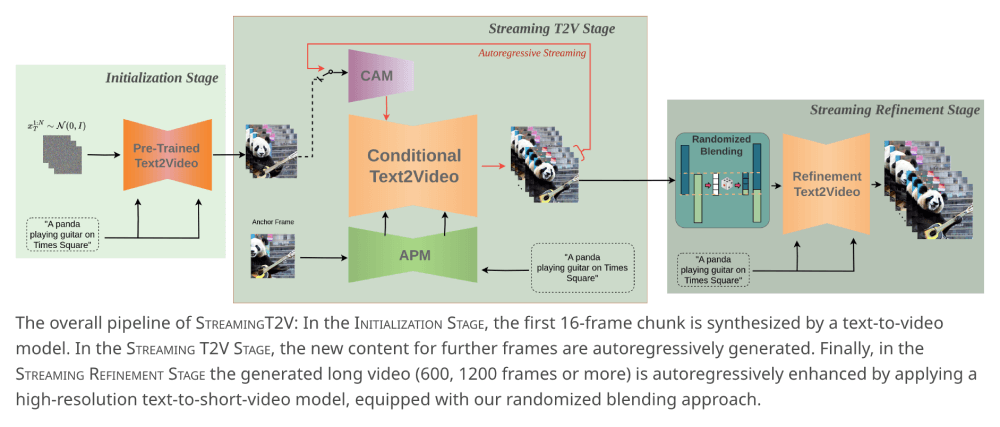
- 初始化阶段:使用预训练的文本到视频模型(如Modelscope)合成一个初始的短视频块,通常是16帧。
- 长视频生成阶段:模型进入自回归长视频生成过程,运用CAM和APM模块生成视频的后续帧。CAM通过注意力机制关注前一个视频块的特征,实现块间平滑过渡;APM则从初始视频中提取关键视觉特征,确保视频中场景和对象的一致性。
- 视频细化阶段:生成一定长度的视频后,模型会使用高分辨率的文本到视频模型(如MS-Vid2Vid-XL)进行自回归增强。通过随机混合技术对24帧视频块进行增强,提高视频的整体质量和分辨率。
StreamingT2V模型以其创新的技术,为文本到视频的长内容生成开辟了新道路,展现了AI在视频内容创作领域的强大潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号