近日,一则引人瞩目的消息传来,基于北京交通大学与中国科学技术大学的联合钻研,豆包大模型团队所提出的“VideoWorld”视频生成实验模型正式对外开源。
“VideoWorld”模型的突出特性在于,它摆脱了对传统语言模型的依赖,借助视觉信息就能实现对世界的认知与理解。这一创新性突破的灵感,源自李飞飞教授在TED演讲里提及的幼儿不依靠语言理解真实世界的理念。
此模型通过对海量视频数据的解析与处理,具备了复杂的推理、规划以及决策能力。研究团队的实验表明,即便在仅有300M参数的情况下,“VideoWorld”也取得了颇为显著的成效。与现有的依赖语言或标签数据的模型有所不同,它能够独立开展知识学习,在折纸、打领结等复杂任务中,提供更为直观的学习模式。
为了验证“VideoWorld”模型的有效性,研究团队搭建了围棋对战和机器人模拟操控这两种实验环境。围棋作为高策略性游戏,能有效评估模型的规则学习与推理能力,而机器人任务则可考察模型在控制与规划方面的表现。在训练阶段,模型通过观看大量视频演示数据,逐步构建起对未来画面的预测能力。
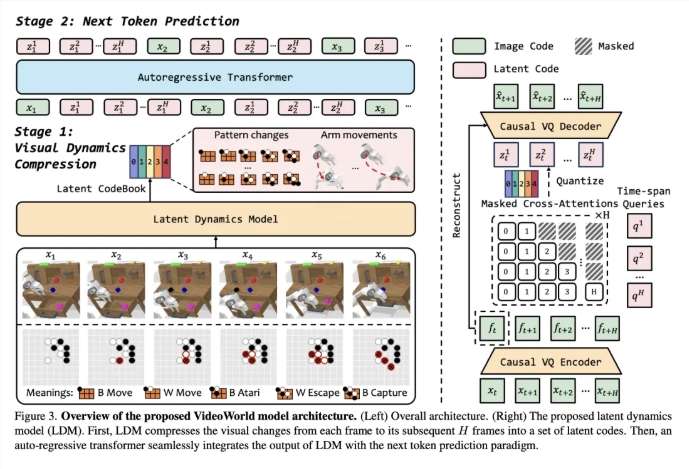
为提升视频学习效率,团队引入潜在动态模型(LDM),旨在压缩视频帧间的视觉变化,进而提取关键信息。这一举措不仅减少了冗余信息,还增强了模型对复杂知识的学习效率。凭借这一创新,“VideoWorld”在围棋和机器人任务中彰显出出色能力,甚至达到专业五段围棋的水平。
论文链接: https://arxiv.org/abs/2501.09781
代码链接: https://github.com/bytedance/VideoWorld
项目主页: https://maverickren.github.io/VideoWorld.github.io
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号