2025年春节前期,AI企业DeepSeek连续发布V3和R1两大开源模型,在AI领域激起千层浪。此前,2022年11月[chatgpt](https://ai-kit.cn/sites/1007.html)的问世曾引发全民关注,此后AI行业的重大变革常被称作“ChatGPT时刻”,而“DeepSeek时刻”的出现,被视为AI历史新转折点。
成立于2023年7月17日的DeepSeek,虽为初创公司,却手握大量英伟达芯片。其宣称V3性能接近部分闭源模型,优于开源模型Meta的LLaMA3,且总训练成本仅557.6万美元;推理模型R1效果逼近OpenAI o1,APi价格仅为OpenAI o1的3.7%。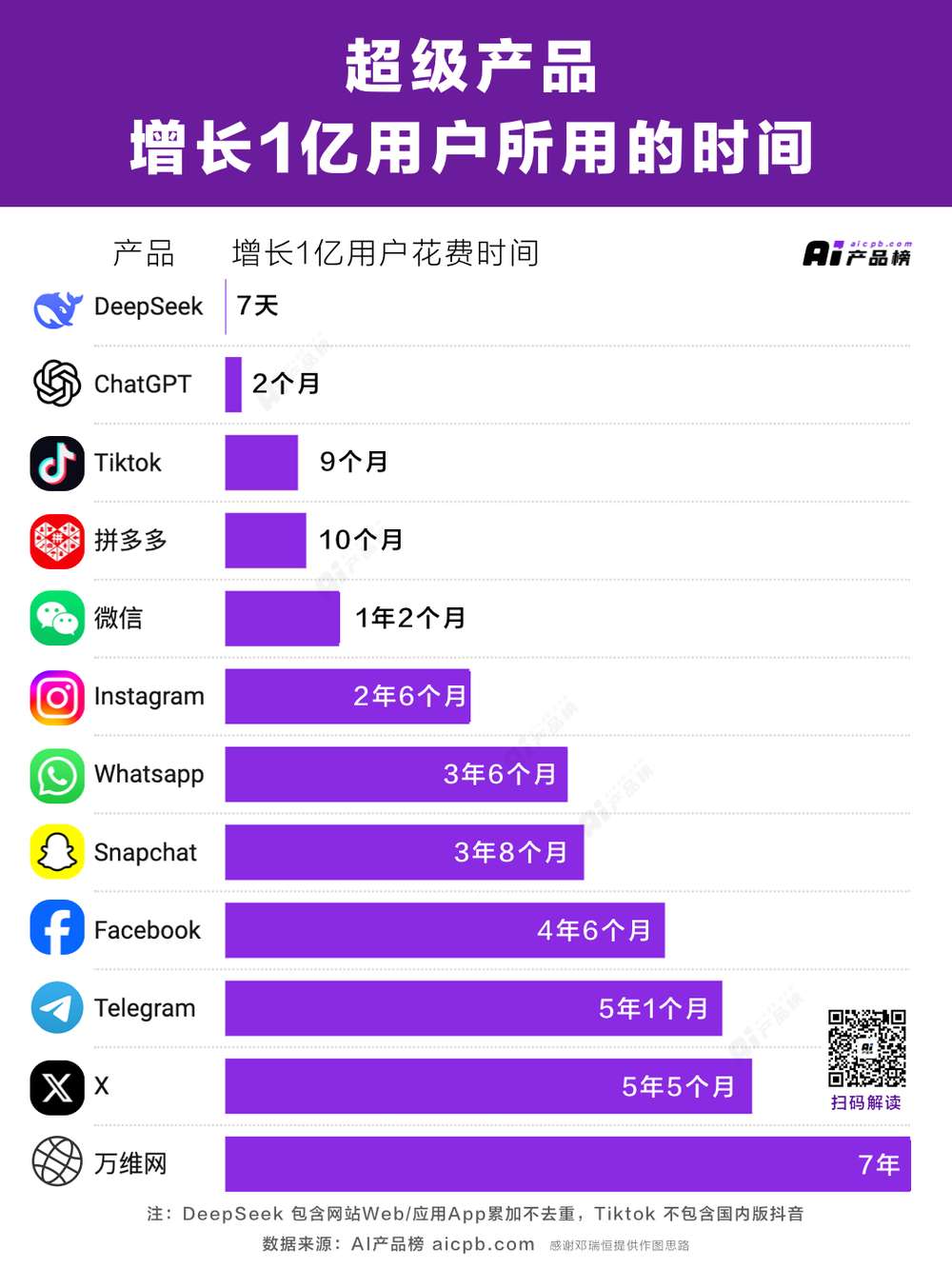
DeepSeek-R1上线后,因其免费使用、展示思维过程、开源技术论文和模型等特点,受到用户欢迎,但也遭遇了服务器受大规模DDoS恶意攻击致宕机的问题。面对“是否有创新”的质疑,DeepSeek在技术论文中回应,V3采用多项自研技术架构创新,R1通过纯强化学习直接训练优化了训练效率。
尽管DeepSeek宣称训练成本低,但考虑服务器资本支出、运营成本等因素,其总成本在4年内可能达25.73亿美元。不过,创新成本下降趋势早已存在,DeepSeek加速了这一进程。其可贵之处不仅在于“便宜”,还在于创始人梁文峰前期的技术和资源储备,为其发展提供了支持。
DeepSeek的火爆对中美AI产业链上下游企业产生冲击。Chatbot类AI应用中,DeepSeek日活超越国内竞品登顶中国第一,仅用一周用户破亿,而ChatGPT用时2个月。这也使部分同类产品声量被盖过,日活受影响。在自研大模型公司层面,DeepSeek的出现促使企业思考训练成本、训练方式和API价格战等问题。
在芯片市场,虽然英伟达股价因DeepSeek下跌,但算力需求随着模型应用场景扩展而增大,英伟达并非真正受害者。同时,DeepSeek验证了国内AI产业从芯片到模型可部分实现国产替代,提振了产业信心,春节期间国内云服务厂商和GPU厂商纷纷部署。然而,市场担忧DeepSeek接受战略投资后会失去自由发展的优势。
从更大视角看,DeepSeek的崛起体现了AI产业“算力军备”和“算法效率”两种路径的对比。以往大模型公司多押注“算力军备”范式,而DeepSeek采用“算法效率”范式,以低成本高性能模型入场。在“高质量文本训练数据即将被消耗殆尽”的行业背景下,“算法效率”范式的可行性得到证明。
尽管如此,业内人士认为不应过分乐观。近期几大海外巨头推出新模型,且数据工程等方面的优势成为大厂的护城河。此外,DeepSeek选择工程优化路径,其在能力上限突破方面面临挑战。但不可否认,DeepSeek搅动了AI行业,其影响还在持续扩大。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号