2025年春节前夕,AI领域迎来重大变革。中国杭州的DeepSeek公司,于2024年12月26日和2025年1月20日先后推出V3和R1两大开源模型,在全球范围内掀起波澜。
据了解,DeepSeek成立于2023年7月17日,作为一家初创企业,却手握万张英伟达芯片。其推出的V3模型在性能上逼近闭源模型[GPT-4](https://ai-kit.cn/sites/1023.html)o与Claude-3.5-Sonnet,超越开源模型LLaMA3,且总训练成本仅557.6万美元;推理模型R1的效果则逼近OpenAI o1,APi价格仅为OpenAI o1的3.7%。
DeepSeek的崛起,打破了AI行业的传统格局。其模型不仅完全免费使用,还在与用户聊天时展示思维过程,提升对话体验。同时,该公司毫无保留地开源技术论文和模型,赢得了用户的广泛认可。然而,这也引发了海外巨头的不满。OpenAI指责DeepSeek“蒸馏”其模型,Anthropic创始人则呼吁加强对中国的算力出口管制。
面对质疑,DeepSeek在技术论文中回应称,V3模型采用多项自研技术进行架构创新,包括DeepSeekMoE+DeepSeekMLA架构、MTP多Token预测技术,使低成本训练成为可能;R1模型放弃传统RLHF中的HF部分,通过纯强化学习直接训练,优化了训练效率。
尽管DeepSeek宣称训练成本低,但半导体市场分析公司指出,557.6万美元仅为模型预训练的GPU成本,考虑到服务器资本支出、运营成本等因素,其总成本在4年内可能达到25.73亿美元。不过,创新成本下降的趋势早已存在,DeepSeek只是加速了这一进程。
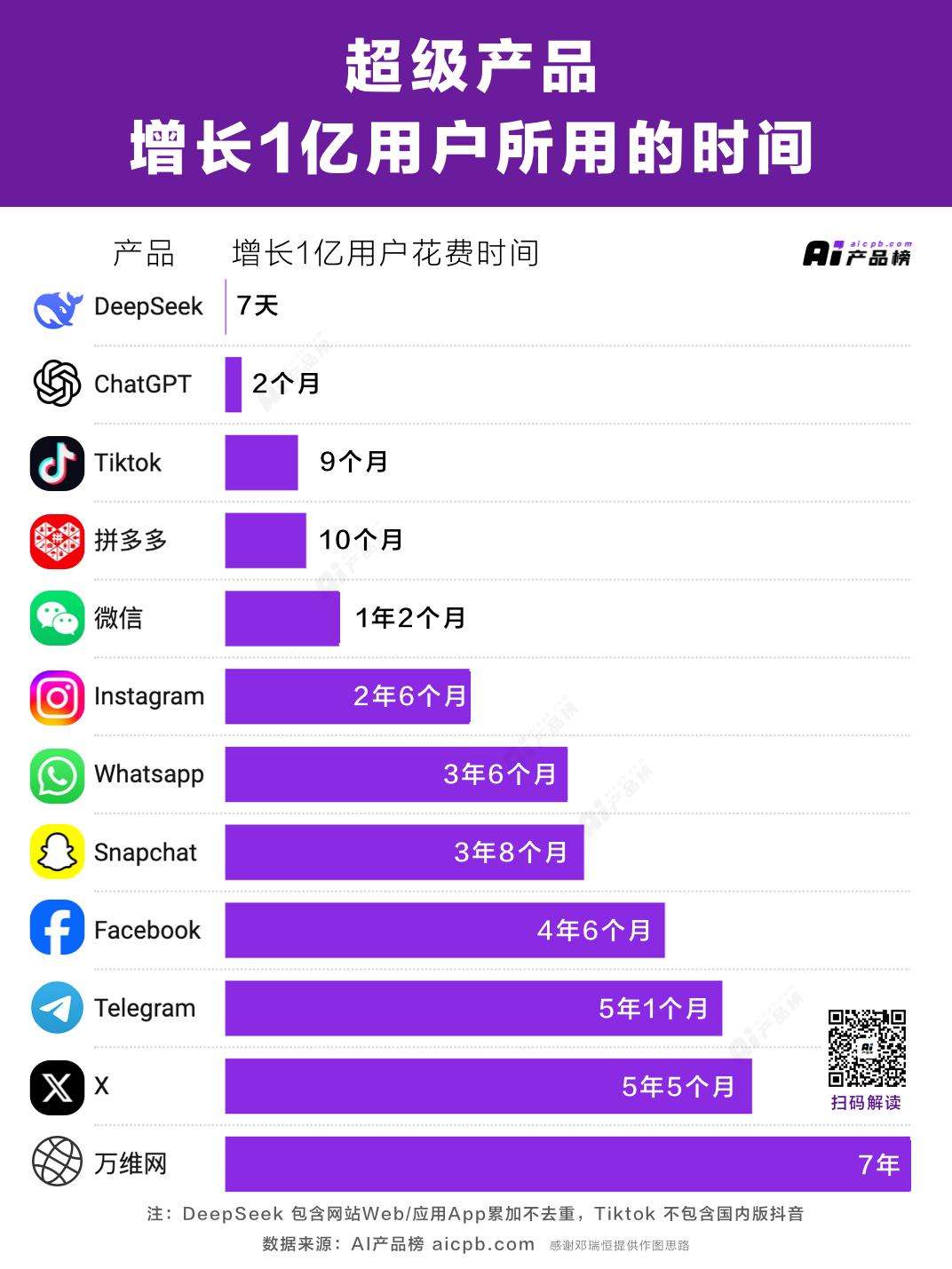
DeepSeek的爆火,对中美AI产业链上下游企业产生了巨大冲击。在chatbot类AI应用领域,DeepSeek日活超过2000万,超越国内的豆包和Kimi登顶中国第一,仅用一周就用户破亿,而[chatgpt](https://ai-kit.cn/sites/1007.html)用时2个月。这表明用户对chatbot模式的忠诚度较低,一旦出现更强大、更便宜、更快的模型,用户就会迁移。
在自研大模型公司层面,DeepSeek的出现使得六小龙的格局基本瓦解。投资人认为,国内巨头中,阿里的Qwen表现出色,豆包在2024年下半年提升明显;创业公司里,DeepSeek和月之暗面增长迅速,其余五小龙则增长缓慢。
至于芯片市场,多位行业人士表示,算力之争不会消失,但现在到了重估阶段。英伟达股价虽受影响,但最终价值仍会上升,因为模型应用场景的扩展将增加对算力的需求。同时,DeepSeek验证了国内AI产业从芯片到模型可以部分实现国产替代,提振了产业信心。
从更大视角来看,DeepSeek的崛起背后是两种路径的对比。以往大模型公司多采用“算力军备”范式,而DeepSeek选择了“算法效率”范式,以产业落地为目标,推出低成本高性能模型。这一范式的可行性得到了验证,也让美国AI巨头的资本故事受到挑战。
然而,DeepSeek也面临着诸多挑战。近期,几大海外巨头推出了新模型,如OpenAI的o3-mini系列和谷歌的Gemini2.0家族更新。此外,有业内人士认为,DeepSeek专注于工程优化,可能难以在能力上限上取得突破。
总之,DeepSeek搅动了AI行业的这片汪洋,其未来发展充满变数。我们将持续关注其动态,见证AI行业的变革与发展。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号