在大模型领域,人们虽对其有所听闻且进行过对话测试,但误解颇多,对其开发过程更是知之甚少。性能卓越的Deepseek开源后,令人惊喜的是,大模型部署变得轻而易举。
一位朋友在3000多元的联想lecoo酷310 PC机上成功安装了DeepseekR1。即便机器配置不高,安装的是7B(70亿)参数版本,聊天能力稍弱,但性能最强的671B版本,在PC机上也能实现部署,国外有人在6000美元的机器上就安装成功了。
大模型开发包含训练和推理两种场景,训练难度高,推理相对简单,人们熟知的多为推理。训练产生的“权重”能生成不同性能版本,权重文件大小各异。有了权重文件,大模型推理并不复杂,即便对机器学习不太了解的人,阅读本文后也能掌握。
大模型科普文章众多,可公众仍对其运作原理感到困惑,原因在于总要提及“Transformer”,解释它需诸多前置概念。本文另辟蹊径,从“矩阵”角度解释大模型推理运行机制,即便不了解Transformer也能理解。
从与大模型对话的推理使用经验和简单程序知识出发,解析大模型推理。大模型最直观的输入输出行为,即用户输入prompt,大模型经搜索、思考后输出反馈。用户还可开启“联网搜索”和“深度思考”功能,其中“深度思考”是Deepseek率先引入的特性,会展示思考过程。
大模型反馈输出的文字通过“自回归”方式生成,即重复调用,将生成的新词加到prompt后。例如,用户输入特定prompt,大模型产生“sampletoken”,加到prompt后再次运算,直至生成完整句子并终止运算。大模型依据特殊标记、输出长度界限或内部逻辑判断终止运算。运算后,大模型会给出多种输出选择,其概率组合构成logits,开发者可据此评估模型性能。最终输出会根据概率或随机性确定,“温度”参数可控制输出的稳定性和灵活性。

理解大模型中间计算过程,需了解“token”和“embedding”。token即词元,负责将输入文字分类,跨语言存在,大模型的token种类繁多,如DeepseekV3有129280种。每个大模型都有“tokenizer”将输入和训练语料转换为token。而embedding将token转化为向量,在大模型中向量维度极大,如DeepseekV3的671B版本中,一个token经embedding会变成7168维向量。这一过程标志着大模型之“大”的开始,进入正式矩阵处理阶段。每个token对应固定向量,可初始化生成“词元嵌入矩阵”,供查表使用。一个prompt的多个token经embedding后合成为矩阵,计算过程涉及多个“中间矩阵”,最终转化为logits概率向量。
Deepseek开源了权重和推理代码。权重方面,DeepseekR1的6710亿参数版本性能最强,还有多个小参数版本,部分是与阿里开源的Qwen“联合培养”或改进Meta的LLaMa系列而来。推理代码方面,DeepseekV3的推理源码用python语言编写,最大代码文件model.py仅800行,加上其他源文件约1500行。DeepseekR1与V3结构相同,R1由V3改进而来,通过“强化学习”提升能力,二者权重不同,V3的推理代码可直接用于R1。
从Deepseek V3推理源码的model.py开头几行可知,其实现了fp8的gemm,将8比特浮点数用于大模型开发,加速运行。同时,从“importtorch”可知其采用了Meta的PyTorch深度学习框架。Meta开源的LLaMa大模型及PyTorch开源社区推动了全球机器学习与大模型研发,Deepseek的开源进一步壮大了开源社区。
Meta的LLama大模型有C++工程源码用于推理,核心的llama.cpp有1万行,加上其他源文件共3万多行,底层实现详细。LLama源码中的张量运算库ggml支持多种平台和硬件,其中出现的cuda与英伟达GPU相关。不过,大模型推理并非必须英伟达GPU,其他GPU甚至CPU也可,这表明大模型推理计算相对简单。
大模型的矩阵计算分层进行,每个layer为TransformerLayer。许多大模型科普文章从经典的Transformer结构图展开,但该图概念复杂,且最初用于机器翻译,与当前流行的GPT大模型架构不同。GPT大模型用于文本生成,架构为“纯Decoder”,以embedding矩阵为输入解码输出token。从推理应用角度看,GPT大模型比机器翻译简单,直接学习其推理架构更易理解。
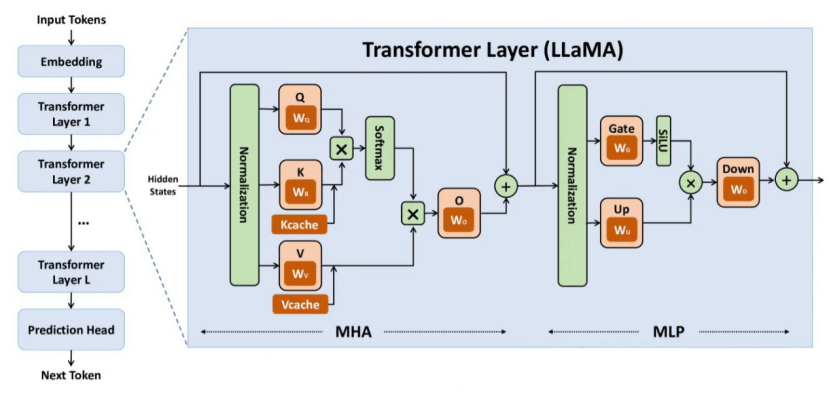
以Deepseek V3和LLaMa为例,不同参数版本的模型,其TransformerLayer层数不同,参数少则层数少。每个Layer输出作为下一个Layer输入,维度保持一致,最终输出变换为logits概率向量。每个layer结构相同但参数矩阵不同,大模型的威力蕴含在这些参数矩阵中,推理时从权重文件读取。
Layer内部计算过程,以前半部分为例,输入矩阵先进行Norm操作,即对向量进行归一化并乘以“缩放因子”;接着进行Self-Attention操作,通过四个方阵与Norm输出矩阵相乘,建立prompt中token间的联系,生成K、Q、V矩阵,Q与K的转置矩阵相乘得到KQ方阵,经掩码操作后与V矩阵相乘得到KQV矩阵。KQV矩阵与Input矩阵相加,即“残差连接”,可加强训练稳定性。
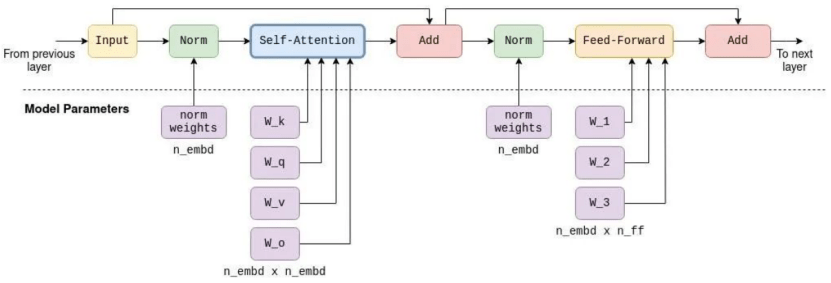
后半部分先是类似的Norm操作,然后是“残差连接”,主要理解Feed-Forward前馈神经网络。FF网络有一个隐藏层,其维度在不同模型中有不同数值,如Deepseek V3中对应参数inter_dim为18432,LLaMa7B中n_ff为11008。FF网络通过矩阵乘法和激活函数实现输入向量维度的升降。
最后一个TransformerLayer输出后,通过乘以固定的output矩阵得到logits概率向量,我们关注其最后一行代表的向量,它决定下一个token的输出可能性。
实际代码中是张量运算,比矩阵运算多了维度。本文介绍的是大模型推理基本结构,理解后有助于学习更复杂的概念。大模型推理过程存在优化空间,但本文旨在帮助读者建立基本理解。
大模型训练比推理复杂,需组织训练过程并优化利用英伟达GPU,但基本操作类似,还原到向量和矩阵运算即可理解。
Deepseek的“联网搜索”和“深度思考”功能值得关注。不联网、不深度思考时,大模型依据内部权重回答问题,存在“幻觉”问题。“联网搜索”通过内置工具调用搜索引擎,获取结果后整合到知识体系生成输出,该功能智能且耗费算力。
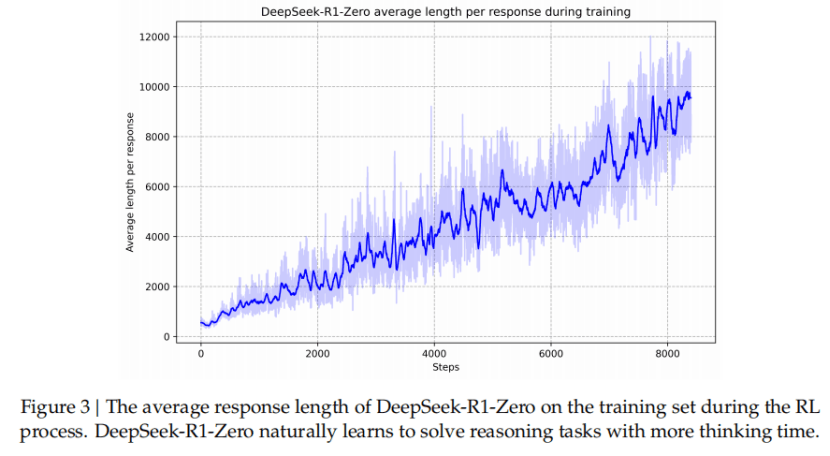
“深度思考”是大模型开发前沿技术,DeepSeek率先向用户展示中间结果。此前业界认为需人为准备COT素材进行SFT教会大模型深度思考,但效果不佳。Deepseek让V3通过“强化学习”自我摸索,生成COT并据此修改系数,最终进化为R1-Zero,后经优化开发出R1,输出对用户友好。应用“深度思考R1”时,COT思考中间输出结合大模型知识体系,给出更具逻辑性的最终输出。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号