在人工智能技术推进进程中,视觉与文本数据的融合难题亟待解决。传统模型面对表格、图表等结构化视觉文档,自动内容提取与理解能力受限,影响了数据分析等多领域应用。在此背景下,IBM适时推出Granite-Vision-3.1-2B,一款聚焦文档理解的小型视觉语言模型。
Granite-Vision-3.1-2B功能强大,能从各类视觉格式中精准提取内容。它基于精心筛选的数据集训练,数据源于公共和合成源,可应对多种文档相关任务。作为Granite大型语言模型的升级版,该模型整合图像和文本两种模态,显著提升了解读能力,在众多实际场景中均可发挥作用。
此模型由三个关键部分构成。视觉编码器运用SigLIP高效处理和编码视觉数据;视觉语言连接器作为带有GELU激活函数的双层多层感知器,负责连接视觉与文本信息;大型语言模型基于Granite-3.1-2B-Instruct,具备128k的上下文长度,可处理复杂庞大输入。
训练时,Granite-Vision-3.1-2B借鉴LlaVA,融合多层编码器特性与AnyRes中更密集的网格分辨率。这些改进增强了模型对详细视觉内容的理解,使其在视觉文档任务中表现更精准,如分析表格图表、进行光学字符识别以及回答文档相关查询。
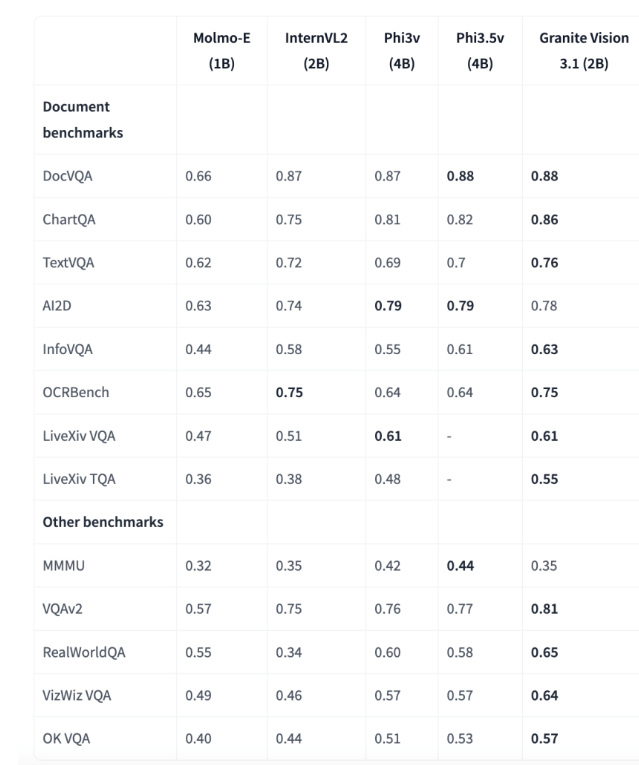
评估结果彰显了Granite-Vision-3.1-2B的卓越性能。在多个基准测试里,它成绩斐然,尤其在文档理解方面优势突出。在ChartQA基准测试中得分0.86,超越同参数范围模型;在TextVQA基准测试中得0.76,展现出解析和回答图像中文本信息的强大实力,凸显其在企业应用中处理精确视觉和文本数据的潜力。
IBM的Granite-Vision-3.1-2B是视觉语言模型领域的重要进展,提供了高效的视觉文档理解方案。其架构和训练方法使其能有效解析复杂视觉和文本数据。因对变换器和vLLM的原生支持,该模型可适应多种用例,能在云环境中部署,为研究人员和专业人士增强AI驱动文档处理能力提供实用工具。模型链接:https://huggingface.co/ibm-granite/granite-vision-3.1-2b-preview 。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号