近期,DeepSeek的V3模型引发了AI领域的广泛关注。该模型仅用557.6万的训练成本,便实现了与OpenAIO1推理模型相近的性能,在全球范围内激起千层浪。
从技术创新角度来看,DeepSeekV3采用了GRPO(分组相对策略优化)的方法,对基础模型能力提升起到关键作用。其在模型架构效率方面进行了诸多优化,例如混合专家网络(MoE)的负载均衡优化,以及在AttentionLayer上节省键值缓存(KV Cache),这些举措使得基础模型在600多B的大模型上展现出不错的能力。
在对芯片市场的影响上,DeepSeek冲击了英伟达两大壁垒——NVLink与CUDA。MOE的优化削弱了英伟达互联的部分重要性,同时在CUDA方面,DeepSeek证明可直接调用更底层的库PTX进行优化,虽未完全绕开CUDA生态,但为行业提供了新的可能性,一定程度上冲击了英伟达的溢价。
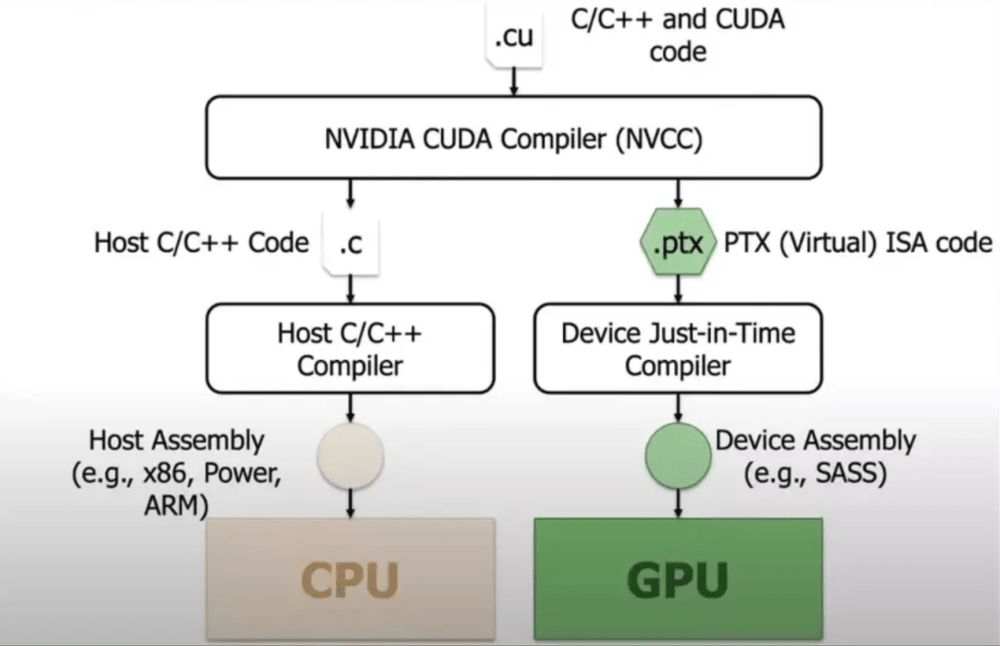
此外,DeepSeek选择开源,这对行业生态意义重大。它降低了AI应用的准入门槛,让更多开发者有信心进行应用开发,通过更多人的使用和反馈,模型也能不断优化。在API价格方面,DeepSeek通过从PTX调用到架构等多方面的优化,降低了对芯片的要求,从而大幅降低了API成本。
展望未来,DeepSeek的持续创新能力备受关注,其数据构成和底层创新细节若能进一步公开,有望为行业发展带来更多启示。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号