AI领域知名人物AndrejKarpathy(卡帕西)宣布全职投身教育领域后,带来了新年的重磅课程——三个半小时的视频课。这一课程聚焦于ChatGPT等大语言模型的内部工作机制,备受关注。
卡帕西此次的课程内容丰富,不仅详细阐述了模型开发的完整训练过程,还介绍了如何在实际应用中高效运用这些模型,同时对AI未来发展趋势进行了探讨。值得一提的是,他强调这门课程专为大众设计,即便没有技术背景的人也能够理解。
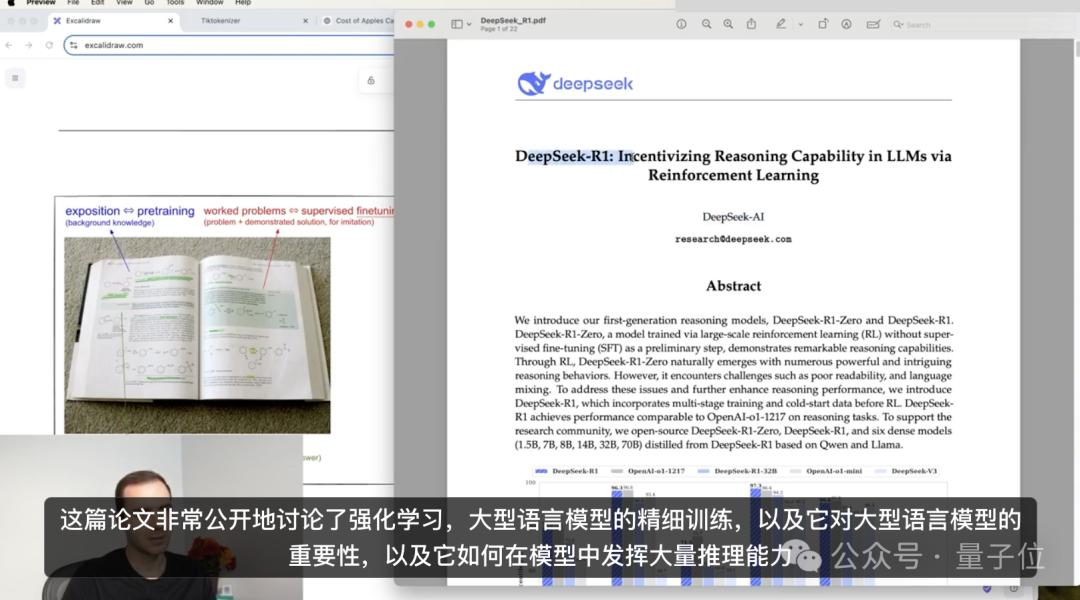
在课程中,卡帕西运用大量具体示例,如GPT-2、Llama 3.1等,深入浅出地讲述了大模型的原理。当红的DeepSeek也成为课程中的重点讲解对象。
课程的含金量极高,一经发布便受到网友的热烈追捧。机器学习工程师Rohan Paul评价其对ChatGPT内部工作机制的解释简洁明了。
下面我们来看看课程中的重点知识点。对于使用过类似ChatGPT工具的人来说,常常会对文本框背后的运行机制感到好奇。卡帕西在视频中针对这些疑问展开解答,从如何构建大语言模型(LLM)讲起,涵盖了多个关键阶段。
首先是预训练阶段。这一阶段旨在让模型积累丰富知识,其第一步是下载和处理互联网数据,从公开资源获取大量多样的文本和高质量文档。接着进行文本提取,将爬虫获取的原始HTML代码转化为网页文本,并进行语言过滤等操作。之后经过去重等步骤,得到大规模文本数据用于训练神经网络。在训练前,需将文本通过字节对编码(BPE)算法转换为一维符号序列,训练时随机抽取token作为输入并预测下一个token,通过不断更新网络参数使预测与实际数据模式一致。训练过程依赖高性能GPU集群,卡帕西还以GPT-2和Llama3为例进行了讲解。不过,预训练模型存在输出随机性和过度记忆训练数据等问题,所以还需要后训练。
后训练阶段,模型通过学习人类标注的对话数据调整行为,具体包括监督微调(SFT)和强化学习(RL)。监督微调阶段,模型学习如何与人类进行多轮对话;强化学习阶段,模型通过实践和试错找到解决问题的最佳方法,卡帕西通过类比人类学习过程进行了详细说明。他还以DeepSeek为例探讨了强化学习在大语言模型中的应用,并介绍了人类反馈的强化学习(RLHF)的工作原理及优缺点。此外,卡帕西提及了多模态模型的发展现状与未来可能出现的持续执行任务的Agent。
卡帕西在AI领域拥有超高人气,这很大程度源于他在教育方面的贡献。他曾在特斯拉、OpenAI任职,后于去年2月从OpenAI离职。他早期通过博客文字分享知识,还推出一系列Youtube视频教程,并与李飞飞合作开设斯坦福大学深度学习课程CS231n。去年7月,他创立了AI原生的新型学校——EurekaLabs,致力于打造“教师+人工智能的共生”模式,目前该实验室官方GitHub账号上已有相关课程。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号