近期,AI领域中DeepSeek-V3的表现引发广泛关注。此前与中国科学院院士、清华大学计算机系教授张钹的交流,提及中国企业在算法效率上的努力,而DeepSeek-V3的出现正是这一努力的体现。
从训练成本看,DeepSeek-V3仅用2048块英伟达H800 GPU,耗费557.6万美元完成训练,相比同等规模模型如GPT-4、Llama3.1等,成本大幅降低。但这一成果在舆论场引发误读,实际其训练成本计算有特定逻辑,且存在“隐性成本”,不同计算方式结果差异大。比如Llama 3.1405B,按不同方式计算训练成本差距明显,OpenAI的GPT-4训练成本估算也因计算方式不同而有差异,DeepSeek-V3对标Claude 3.5Sonnet,其训练成本虽大幅降低,但未达“几十分之一”的夸张程度。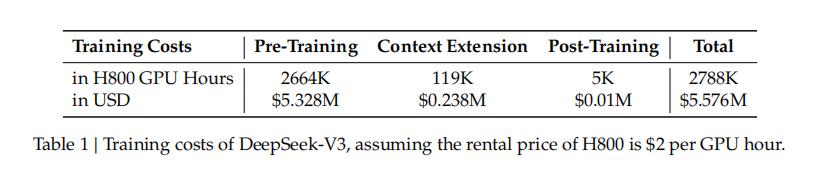
在训练效率方面,DeepSeek-V3表现卓越。它是混合专家模型 (Mixed Expert Models,MoE),采用“大量细粒度的专家”架构,相比其他MoE模型,能更灵活处理数据,提高适应性和泛化能力,且计算效率高、成本低。为提升训练效率,DeepSeek团队在多方面优化。
负载均衡优化上,提出“Auxiliary-loss-free(无辅助损失)”方案,不依赖额外辅助损失,通过在token专家分配中施加bias实现负载均衡,避免传统方案因辅助损失权重设置不当带来的训练不稳定问题,如同动态调整时长的红绿灯优化资源分配。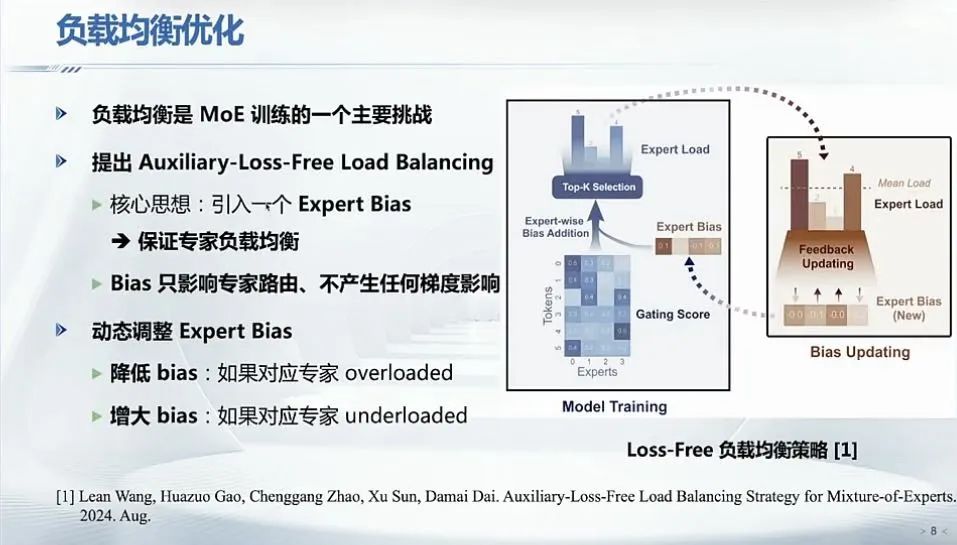
通信优化方面,提出DualPipe算法,核心是将计算和通信阶段重叠,减少GPU空闲期,采用双向流水线机制,从两端处理微批量,保持GPU活跃,还包括跨节点通信优化以及WarpSpecialization技术。
内存优化涵盖重计算、使用CPU内存和参数共享。重计算通过“以时间换空间”策略降低内存消耗,将部分数据存到CPU内存,共享参数空间,节约GPU显存。
计算优化采用混合精度训练策略,引入英伟达FP8混合精度训练框架,在超大规模模型上验证其有效性,实现加速训练和减少GPU内存使用。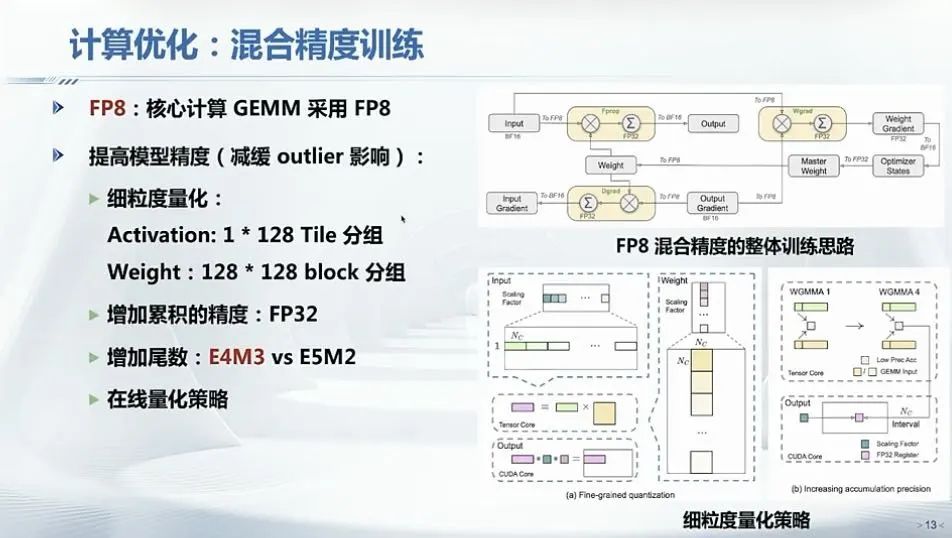
对于DeepSeek的成功,应理性看待。它并非神话,而是“小米加步枪”式的成功。其创新基于对技术细节的深入推敲,从第一性原理思考问题,创始人参与读论文、写代码、搞招聘等,这种朴实的成功内核值得关注。总之,DeepSeek-V3在训练成本和效率上的成果,以及其创新策略,为AI领域发展提供了新的思路和方向。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号