近日,开源AI领域迎来重大里程碑,DeepSeek在GitHub平台上的Star数成功超越OpenAI。其中,热度颇高的DeepSeek-V3的Star数已达7.7万,而DeepSeek-R1仅用3周时间便超越了「openai-cookbook」。这一成绩引发广泛关注,彰显出开源社区的强大力量。
随着DeepSeek的热度飙升,其服务器面临巨大压力,甚至不得不官宣暂停API充值。与此同时,针对DeepSeek的一些说法,专家也进行了辟谣。有观点认为DeepSeek绕过了CUDA架构,实际上,DeepSeek采用的PTX编程仍是英伟达CUDA编程模型的一部分,它能更好地实现对底层硬件的编程和调用,并未摆脱CUDA生态。
关于DeepSeek-R1的训练成本,也存在诸多猜测。此前有说法称大约是600万美元,但开发者指出很多人混淆了DeepSeek-V3和DeepSeek-R1,且DeepSeek团队从未公开过R1确切的GPU小时数或开发成本,现有估算都只是猜测。
DeepSeek V3和R1的发布,对LLM江湖产生重要影响。机器学习大神SebastianRaschka在博文中对其进行硬核预测并破除误解。他介绍了构建推理模型的四种方法以提升LLM的推理能力。
推理时扩展,即在推理过程中增加计算资源,如运用提示工程、投票和搜索策略等。纯强化学习(RL)方面,DeepSeekR1论文亮点是推理行为可通过纯RL产生,DeepSeek-R1-Zero跳过SFT阶段,采用准确性奖励和格式奖励,证明了用纯RL开发推理模型的可行性。
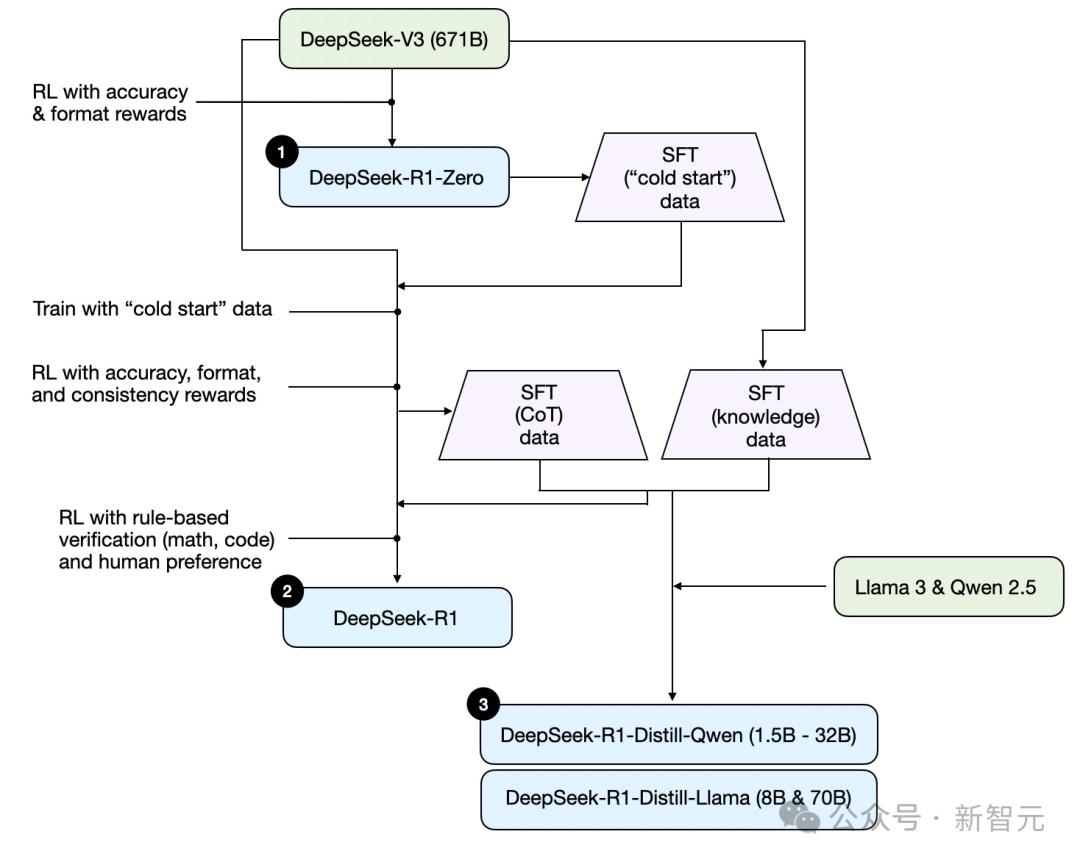
监督微调和强化学习(SFT+RL),旗舰模型DeepSeek-R1通过结合额外的SFT和RL提升推理表现,经过多轮训练性能显著提升。纯监督微调(SFT)和蒸馏则是用较大LLM生成的数据集对较小LLM进行指令微调,结果显示蒸馏对小模型更有效。
对比DeepSeek-R1和OpenAIo1,二者大致在同一水平,但DeepSeek-R1在推理时间上更高效。开发推理模型成本较高,不过模型蒸馏提供了低成本替代方案,如Sky-T1用450美元训练出表现不错的模型,TinyZero借鉴DeepSeek-R1-Zero方法,训练成本不到30美元也展现出推理能力。
此外,旅程学习作为超越传统SFT的方法,不仅让模型学习正确解题路径,还从错误中学习,这一方向在低预算推理模型开发中极具潜力。当前推理模型领域研究活跃,未来值得期待。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号