在文本生成图像技术领域,计算成本随模型规模扩大而飙升的难题亟待解决。英伟达携手MIT、清华、北大等机构研究人员推出的SANA1.5,作为高效可扩展的线性扩散Transformer,带来了创新性突破。

SANA1.5聚焦可扩展性与降低训练成本两大关键问题,提出三项核心创新。首先是高效的模型增长策略,能使SANA从1.6B扩展到4.8B参数,显著减少计算资源消耗,还结合了内存节省的8位优化器。这种策略通过有策略地初始化额外模块,保留小模型先验知识,减少60%训练时间。
其次,引入模型深度剪枝技术。通过分析块的重要性,识别并保留关键块实现高效压缩,再经微调快速恢复模型质量,实现灵活配置。
再者,提出推理期间扩展策略。引入重复采样策略,借助基于视觉语言模型的选择机制,将GenEval分数从0.72提升至0.80,使小模型达到大模型生成质量。
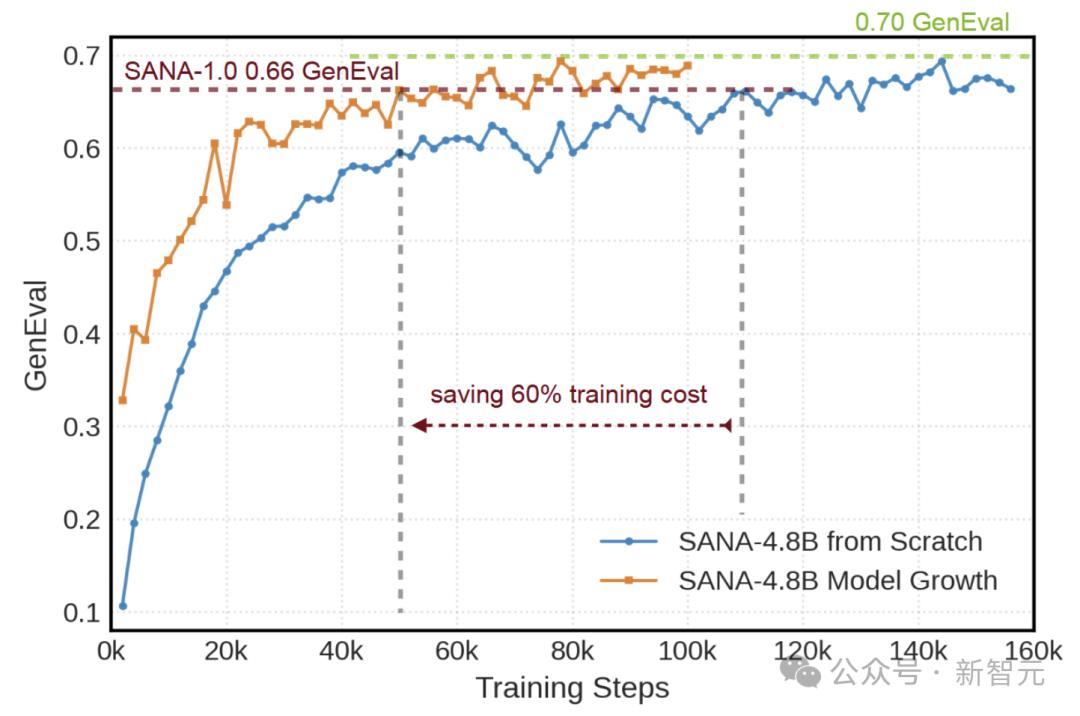
在模型增长方面,研究者探索三种初始化策略后选定部分保留初始化方法,该方法让预训练层与新增层协同,训练动态表现稳定。
模型剪枝上,受Minitron启发,通过输入输出相似性分析块的重要性进行剪枝,剪枝后微调可弥补信息损失,1.6B参数模型经剪枝微调后达到与4.8B相近质量。
推理时扩展中,增加采样次数配合视觉语言模型筛选,提升生成图像与文本提示的匹配度。
此外,CAME-8bit优化器相比AdamW-32bit减少约8倍内存使用,单GPU微调场景中优势明显,如RTX 4090就能微调SANA 4.8B。
评估结果显示,SANA1.5训练收敛速度快2.5倍,在GenEval基准测试中性能先进。模型增长使各项指标提升,模型剪枝以低成本获高分,推理时扩展提升准确率。
此前的SANA框架也独具优势,其深度压缩自动编码器、线性DiT、仅解码文本编码器以及高效训练与采样策略,让生成图像高质量、低运行要求,降低内容创作成本。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号