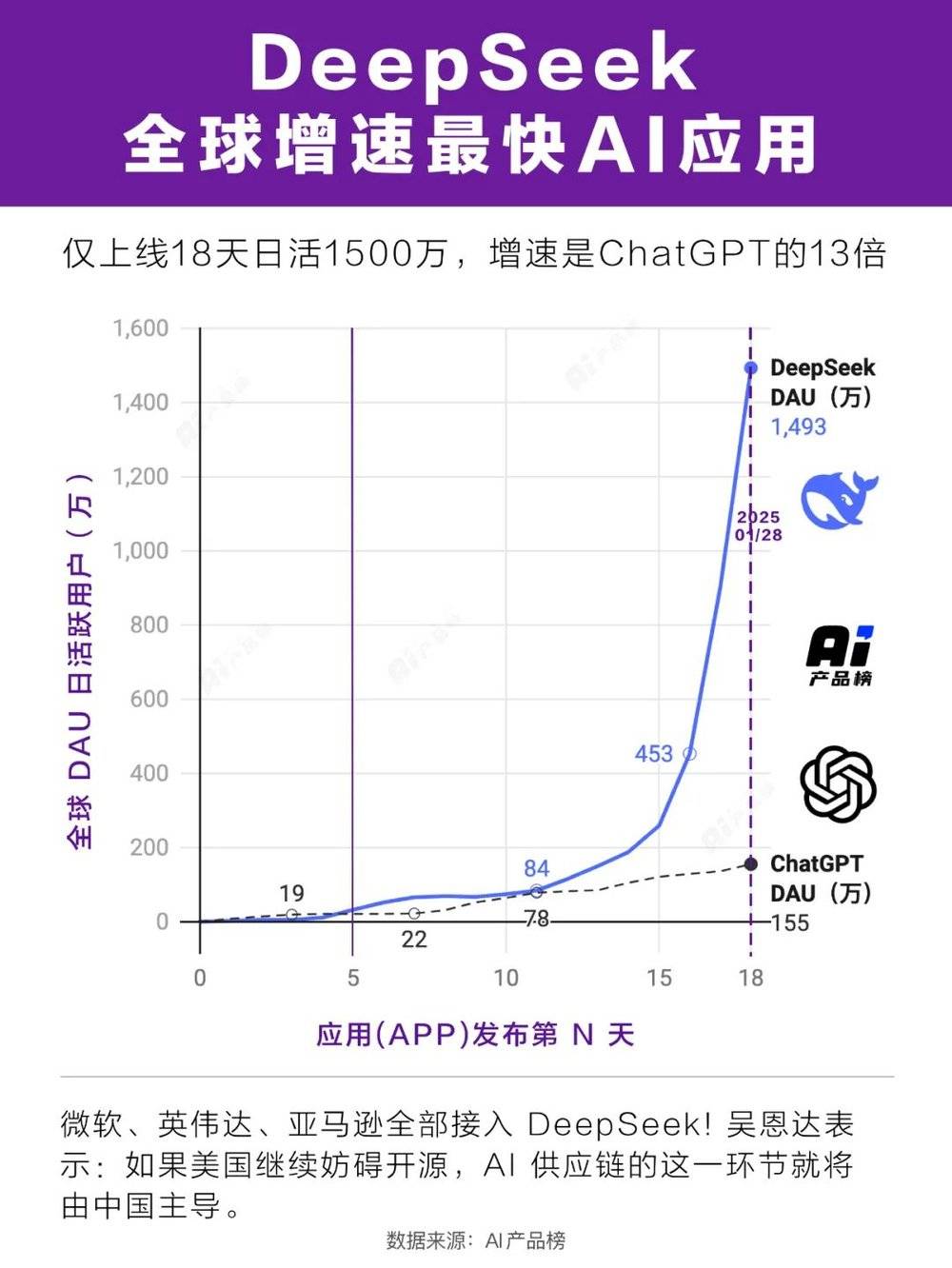
在AI应用的舞台上,DeepSeekapp以惊人之势崛起。上架短短18天,便在全球160多个国家登顶,日活跃用户数突破1500万,成为全球增速最快的AI应用。这一成绩的取得,得益于其发布的免费且无比聪明的模型——DeepSeekR1。
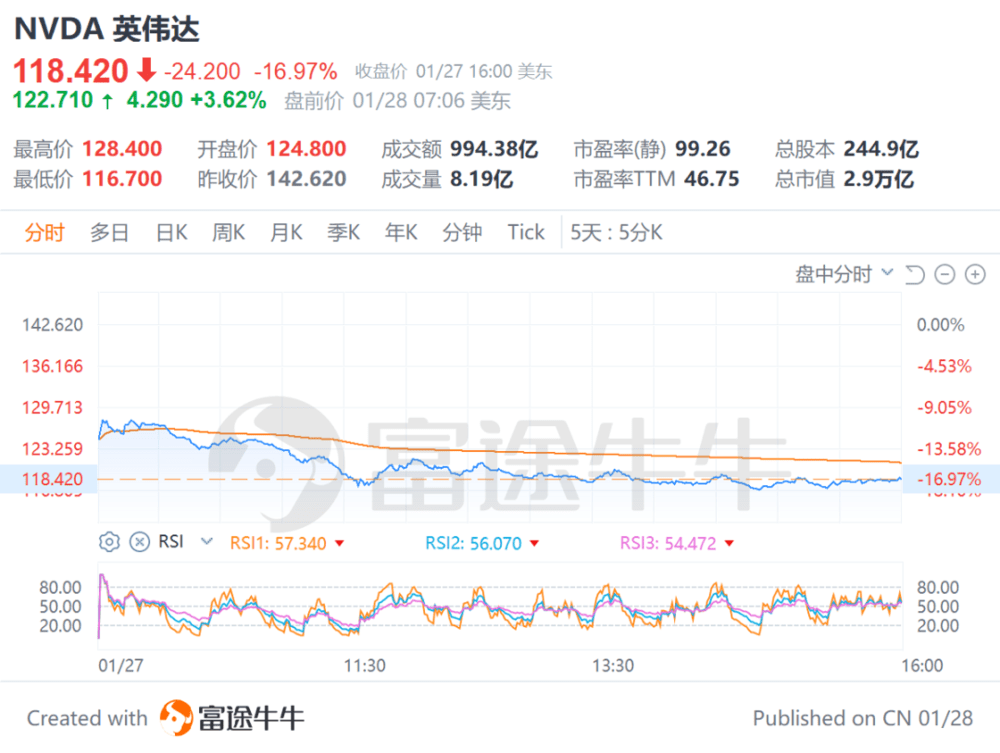
DeepSeekR1的出现,曾一度让美股市值一晚上蒸发超1万亿美金,英伟达股价单日下跌16%。它的“聪明”特性,让大量提示词技巧失效,用户只需简单表述需求,就能获得超出预期的回答。
从大语言模型发展历程来看,2022年11月30日ChatGPT的发布让大模型进入大众视野,而两年后的DeepSeek R1则让优秀模型变得触手可及。
作为一款推理模型,DeepSeek R1与日常使用的对话类AI有很大不同。像OpenAI的[GPT-4](https://ai-kit.cn/sites/1023.html)o、DeepSeekV3、豆包等都属于指令模型,专门用于遵循指令生成内容或执行任务。而DeepSeek R1专注于逻辑推理、问题解决,能够自主处理复杂任务。
值得一提的是,OpenAI的o1也是推理模型,但需付费成为plus会员且使用权限有限。而DeepSeekR1现在完全免费,且在大量写作、写代码任务上甚至比o1更强。
尽管DeepSeek R1相比指令模型有很大进步,但它依然是大型语言模型,存在一定局限性。理解这些特点,有助于更好地应用它。
首先,大模型在训练时将内容token化,所看到和理解的世界与人类不同。例如,在推理模型出现前,很多大模型无法准确回答“Strawberry这个单词中有几个r字母”的问题,这是因为token化会将部分单词拆分,模型看到的是经过编码的token序列。

其次,大模型知识存在截止时间。DeepSeekR1基础模型的训练数据窗口期早在数月前就已关闭,这导致它存在知识滞后性,无法回答一些2024年后发布的模型或2024巴黎奥运会赛事结果等问题。要突破这种限制,可以激活联网搜索功能或补充必要知识。
再者,大模型缺乏自我认知/自我意识。DeepSeek R1不知道自己是谁,也无法告诉你它的特点和使用技巧。
另外,多数大模型包括DeepSeekR1都有上下文长度和输出长度的限制。上下文长度限制使得无法一次投喂太长文档或进行太多轮次对话,输出长度限制则让无法让其一次性完成较长文本的翻译或写作任务。
为了更好地使用DeepSeekR1,有一些有效的技巧。比如提出明确要求,能说清楚的信息不要让其猜测;要求特定风格,R1在特定风格写作上表现出色;提供充分任务背景信息,让结果更符合需求;主动标注自己的知识状态,使输出内容精准匹配理解层次;定义目标而非过程,让R1有思考空间;提供AI不具备的知识背景,帮助其突破知识限制;从开放到收敛,根据R1的推测完善需求,获得更精准结果。

同时,在使用R1时,一些提示词技巧已基本失效。例如思维链提示、结构化提示词、要求扮演专家角色、假装完成任务后给奖励、少示例提示、角色扮演、对已知概念进行解释等,这些策略不仅无效,部分还可能起反作用。
如果还没使用过DeepSeek,有两种官方使用方式:访问DeepSeek官网https://chat.deepseek.com/,或在AppStore或安卓应用商店搜索“DeepSeek”下载免费使用。在使用时,注意聊天输入框下方的“深度思考R1”和“联网搜索”选项,根据需求合理选择。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号