自春节以来,DeepSeek热度持续攀升,伴随而来的是诸多误解与争议。这些争议主要集中在底层创新、成本、计算资源利用、技术依赖以及商业部署与未来发展等方面。
在底层创新方面,关于DeepSeek是否为底层创新存在两种极端观点。一种观点将其技术突破视为“颠覆性革命”,另一种则认为是对国外模型的模仿,甚至猜测通过蒸馏OpenAI模型取得进展。实际上,DeepSeek是一次面向产业痛点的工程范式升级,为AI推理开辟“少即是多”新路径。它在训练架构、评估标准和数据策略三个层面进行创新,虽未突破深度学习理论边界,但解决了产业痛点。其开发的MHA机制变体、GRPO算法以及DualPipe方法,分别在内存利用、算法效率和多GPU训练效率上有所提升。并且,从技术角度看,由于ChatGPT未开放相关数据,基本不可能“蒸馏”ChatGPT,DeepSeek可能仅部分利用蒸馏语料信息进行验证,并非决定性因素。
成本方面,DeepSeek-V3论文中提到的550万美元成本数据存在争议。这一数字未计入强化学习训练的额外成本,且只是最终训练运行成本,未涵盖前期实验等成本。同时,研究人员薪资等其他成本也未计算在内。不过,基于GPU成本等多项分析,550万美元的净算力成本已十分高效。

对于巨额资本支出投资算力是否是浪费这一观点,虽DeepSeek在训练效率上有优势,但从扩展定律来看,更多计算能力意味着更好性能,AI发展核心规律未变,更多计算资源仍能带来更好效果。
在技术依赖上,DeepSeek论文提到采用PTX编程以释放底层硬件性能。对于此,网络有“绕开CUDA垄断”和“解决芯片互联带宽问题”两种解读。然而,上海交通大学副教授戴国浩指出,PTX指令位于CUDA驱动层内部,依赖CUDA生态系统,该优化是主动行为,可提高通信互联效率。
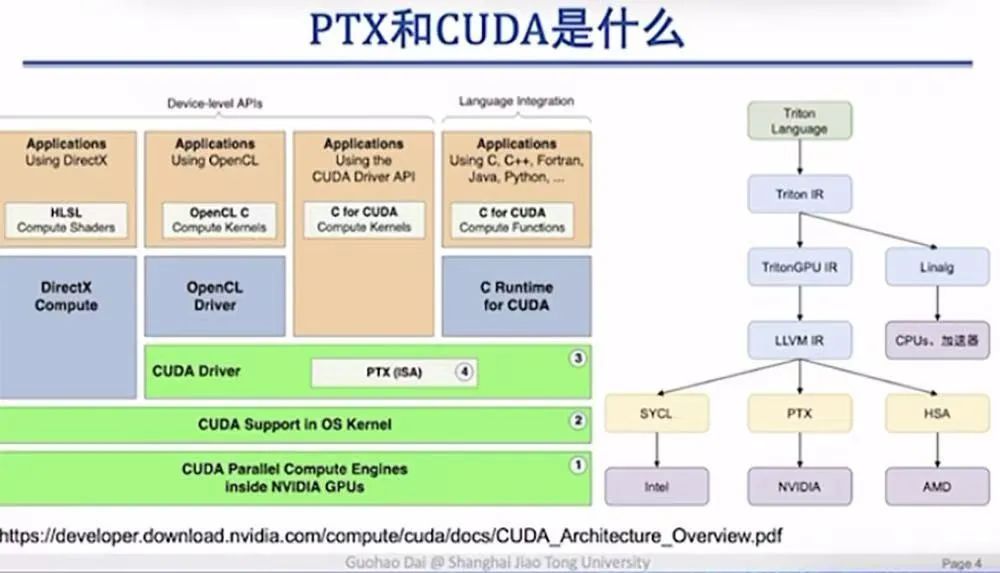
商业部署与未来发展方面,DeepSeek爆火后,国内外众多云巨头纷纷上架或支持部署。但这更多是出于商业考量,并非对其“情有独钟”。同时,网络传言的DeepSeek会被国外禁用也不准确,被限制使用的可能是App,而巨头接入的是开源软件部署。DeepSeek以开源姿态进入全球AI竞技场,其真实价值需时间和市场检验。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号