在提升大模型推理性能的探索中,一种创新方法引发关注。来自斯坦福大学、华盛顿大学、Ai2等机构的研究人员另辟蹊径,提出预算强制技术,打造出极具潜力的s1-32B模型。
此前,OpenAI的o系列模型凭借大规模强化学习与大量数据展现强大性能,DeepSeek-R1模型也通过数百万样本和多阶段强化学习达到o1级别性能,但测试时扩展行为的清晰复现一直无人公开。而此次研究人员证明,仅用1000个样本微调模型,并借助预算强制技术,就能让推理能力随测试计算量增加而提升。

预算强制技术可通过强制提前结束模型思考过程,或重复添加「Wait」延长思考时间,进而影响模型推理深度与最终答案。团队构建的s1K数据集,由1000个精心筛选问题组成,配有推理轨迹和蒸馏而来的答案,为训练s1-32B模型奠定基础。
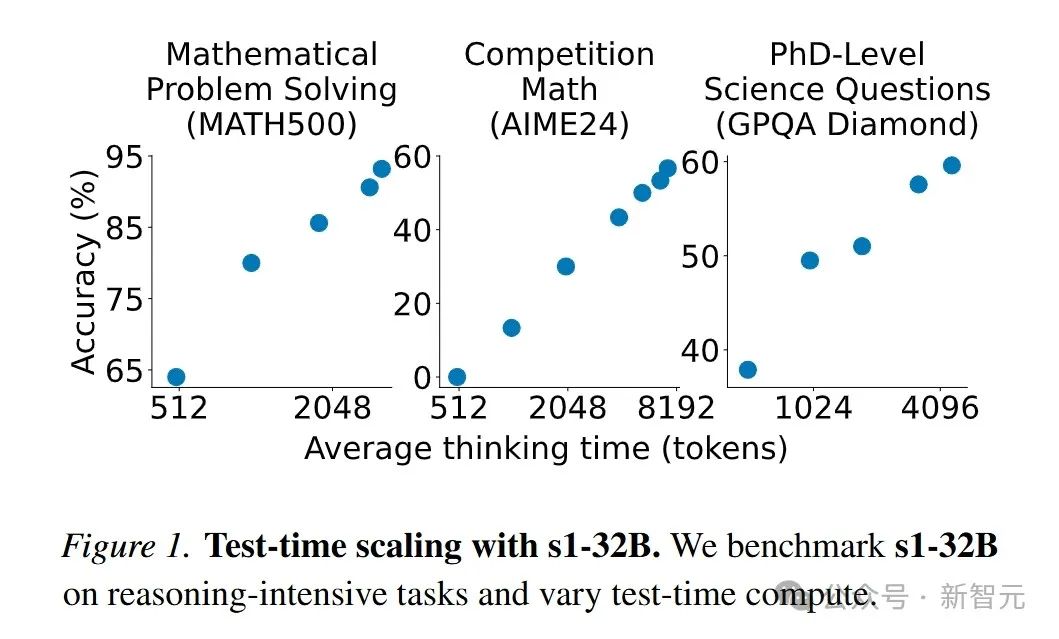
在预训练模型上进行监督微调,仅用16张H100GPU训练26分钟,再结合预算强制技术,s1-32B模型展现出测试时扩展能力,成为最具样本效率的推理模型,在多个基准测试中超越OpenAIo1-preview等闭源模型。
创建s1K数据集分为两个阶段。初始阶段,研究人员从16个不同来源收集59029个问题,遵循质量、难度和多样性原则。第二阶段,通过三个阶段过滤,从59K样本中筛选出1000个样本。最终,s1K数据集涵盖50个不同领域,包含高质量、多样化和高难度问题,并附带推理过程。
测试时扩展方法分为顺序和并行两类,论文重点关注顺序扩展。预算强制作为一种顺序扩展方法,通过限制模型测试时使用的最大和/或最小思考token数量控制计算量,实验证明该方法能引导模型修正答案。
在消融实验中,数据消融实验验证了高质量、多样性和难度相结合是实现样本高效推理训练的关键;测试时扩展方法消融实验表明,预算强制在控制性、扩展性和性能方面优于其他方法。

研究表明,仅在1000个样本上进行监督微调就能构建有竞争力的推理模型。预算强制虽有局限性,但证明了测试时扩展的潜力,为未来研究提供方向。未来可探索改进预算强制的方法,将其应用于强化学习训练的推理模型,以及扩展测试时的计算量。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号