今日凌晨,谷歌有重大动作,正式发布了性能更为强劲的Gemini 2.0 Pro实验版,以及以低价为突出特点的Gemini 2.0 Flash-Lite预览版,同时,轻量级的Gemini 2.0 Flash最新版本也正式开放。
在这些新发布的模型中,Gemini 2.0 Flash-Lite作为Gemini2.0系列的全新变体,展现出突出的成本优势,每百万tokens仅需0.3美元,成为谷歌目前最便宜的模型。而Gemini 2.0Pro实验版则凭借原生多模态能力备受瞩目,能够实现文本和音视频之间的相互转换。值得一提的是,Gemini 2.0Flash的实验版于去年12月首次亮相,如今的最新版本已是完整版。
此外,谷歌还免费开放了Gemini 2.0 Flash Thinking实验版,该版本具备强大的功能,能够访问、提炼并总结YouTube视频内容。
截至发稿时,在Chatbot Arena大模型排行榜上,Gemini 2.0 Flash Thinking实验版和Gemini 2.0Pro实验版表现惊艳,强势冲上榜首位置,综合得分成功反超Chat[GPT-4](https://ai-kit.cn/sites/1023.html)o和DeepSeek-R1,展现出强劲的发展势头。
现在,Gemini 2.0 Flash新版、Gemini 2.0 Pro实验版和Gemini 2.0 Flash-Lite预览版,均能通过谷歌AIStudio和Vertex AI调用其API。这些模型变体在价格和性能方面各有千秋。
据谷歌官网信息,Gemini 2.0 Flash和Gemini 2.0 Flash-Lite侧重于轻量级部署,它们的上下文窗口长度最多支持100万个tokens,并且取消了Gemini 1.5Flash长文本和短文本处理的定价区别,统一按单位token计价。Gemini 2.0Flash目前每百万tokens文本输出的花费为0.4美元,相较于Gemini 1.5 Flash,处理长文本的价格便宜了一半。

同时,Lite版本针对大规模文本输出场景进行了成本优化,每百万tokens文本输出定价0.3美元。谷歌CEO桑达尔·皮查伊用“高效且强大”来形容这款模型。
除了价格优势,谷歌Gemini 2.0的新变体在性能方面也有显著提升。相比于Lite版,Gemini 2.0Flash的多模态交互功能更为全面,按计划可支持图像输出,以及文本、音频、视频等模态的双向实时低延迟输入和输出。
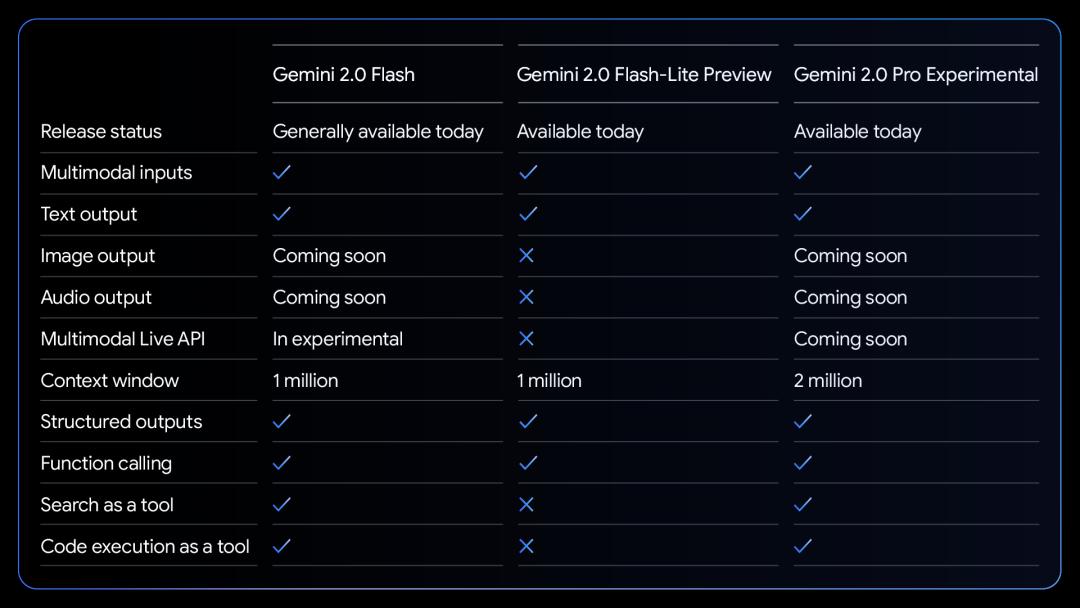
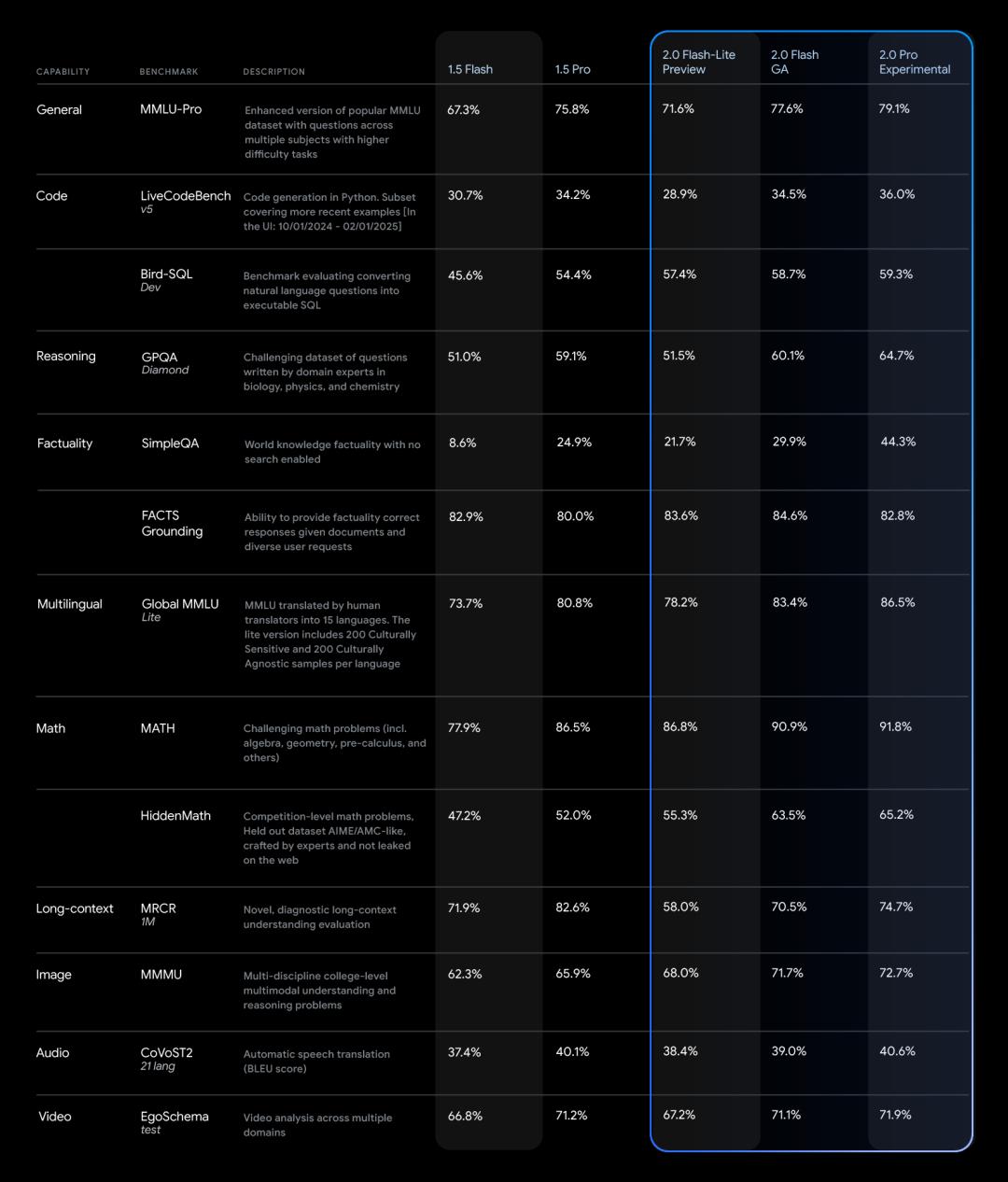
而Gemini 2.0Pro实验版则在编码性能和复杂提示方面表现卓越,成为谷歌自称旗下表现最佳的模型。该模型的上下文窗口可达200万个tokens,通用能力从前代的75.8%提升至79.1%,在编码和推理能力方面与Gemini2.0 Flash、Gemini 2.0 Flash-Lite拉开了明显差距。
Gemini应用程序团队在X上发布消息称,Gemini Advanced用户现在可以通过模型下拉菜单访问Gemini 2.0 Pro实验版,Gemini2.0 Flash Thinking实验版则免费向Gemini应用用户开放。此外,该团队还透露,Gemini 2.0 FlashThinking实验版可以与YouTube、谷歌搜索和谷歌地图联动使用。
受开源、低成本、高性能DeepSeek-R1推出的影响,模型开发成本成为业内关注的焦点。谷歌2024年第四季度财报发布后,在电话会议上,皮查伊肯定了DeepSeek取得的成绩,同时强调Gemini系列模型在成本、性能、延迟三者关系的平衡上处于领先地位,整体表现优于DeepSeek的V3和R1模型。
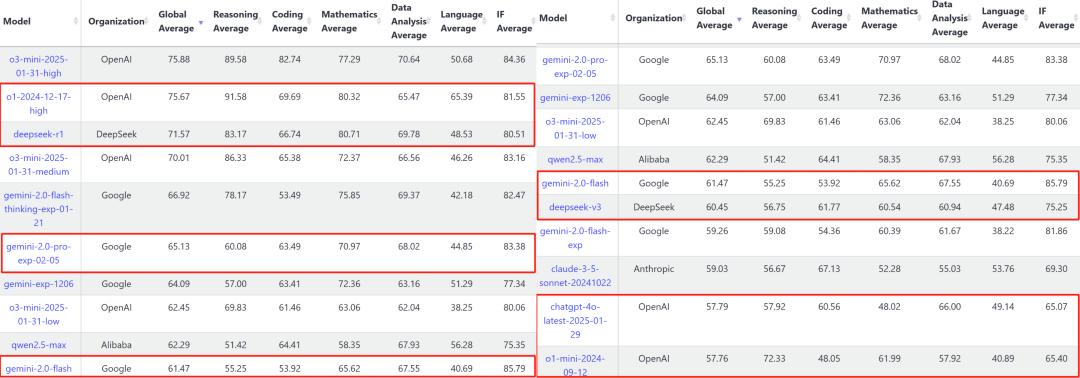
从杨立昆及其团队搭建的LiveBench大模型性能基准测试排行来看,Gemini 2.0 Flash总体排名高于DeepSeekV3和OpenAI的o1-mini,但落后于DeepSeek-R1和OpenAI的o1。
谷歌此次推出的Gemini 2.0 Flash-Lite,无疑是打出了一张“价格牌”。一位长期关注AI领域、在X上拥有近万粉丝的网友,对DeepSeekV3、GPT-4o-mini、Gemini 2.0 Flash进行了试用。该网友表示,新版的Gemini 2.0Flash在性能和成本方面均超越了另外两个模型。
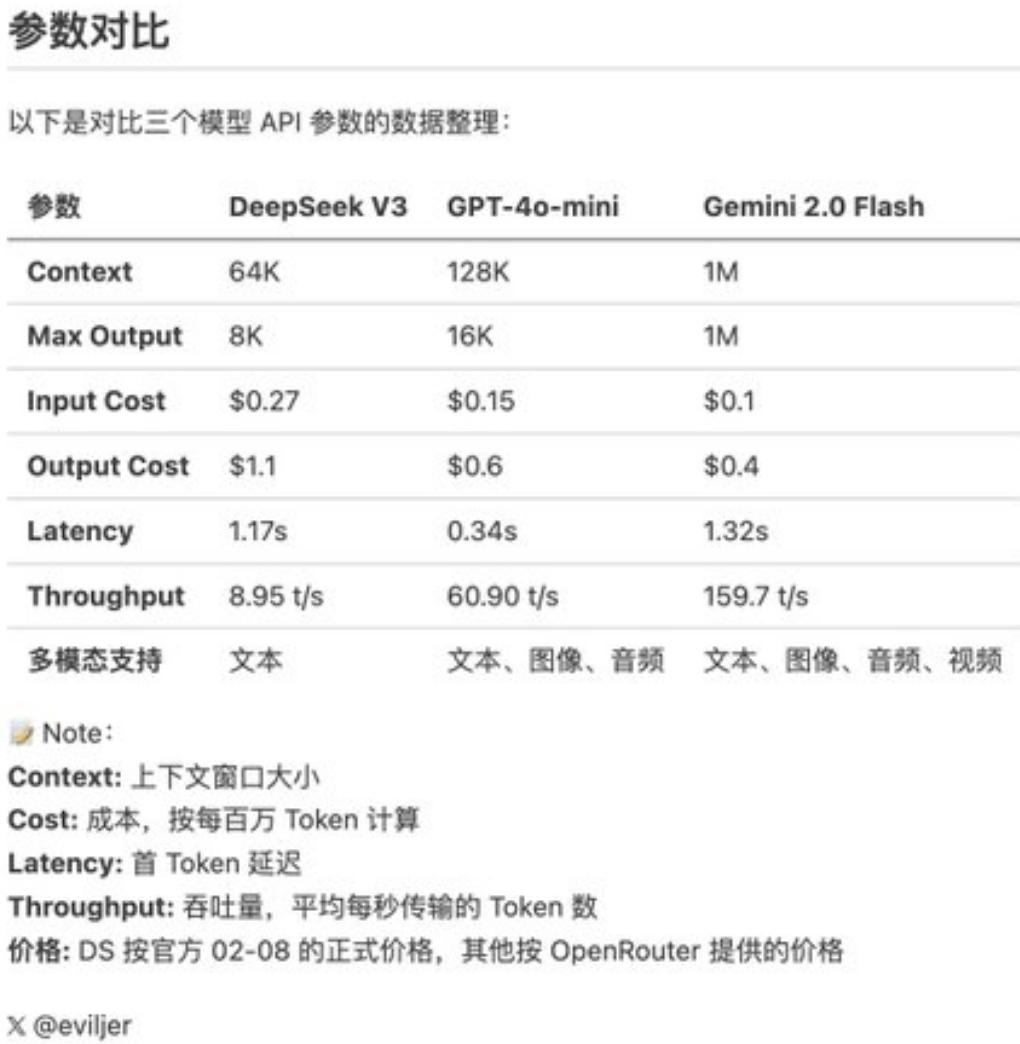
具体而言,Gemini 2.0 Flash每百万tokens的输入成本为0.1美元,输出成本为0.4美元,这两项数据均远低于DeepSeekV3。该网友在X上留言:“Gemini 2.0 Flash正式版成本为GPT-4o-mini的三分之一,同时速度是后者的3倍。”

DeepSeek掀起的大模型价格战,对海外大模型市场的影响仍在持续。谷歌推出更为轻量级的Gemini 2.0 Flash-Lite,OpenAI向所有用户免费开放了ChatGPT搜索功能,Meta内部团队也在加紧研究大模型降价策略。目前来看,大模型领域竞争激烈,各模型通过变相降价来吸引和留存用户。卷性价比有助于大模型从技术开发迈向应用落地阶段。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号