Vectara的机器学习团队,针对DeepSeek系列的两款模型开展了深度幻觉测试。在此次测试里,DeepSeek-R1的幻觉率达到了14.3%,与其前身DeepSeek-V3仅3.9%的幻觉率相比,差距明显。这一数据直观地表明,在增强推理进程中,DeepSeek-R1生成了更多与原始信息不符或不准确的内容。

研究团队表示,推理增强模型相较于普通大语言模型,可能更容易出现幻觉现象。这一点在DeepSeek系列与其他推理增强模型的对比中,体现得极为显著。就拿GPT系列来说,推理增强的GPT-o1和普通版[GPT-4](https://ai-kit.cn/sites/1023.html)o之间的幻觉率差异,进一步验证了这一推测。
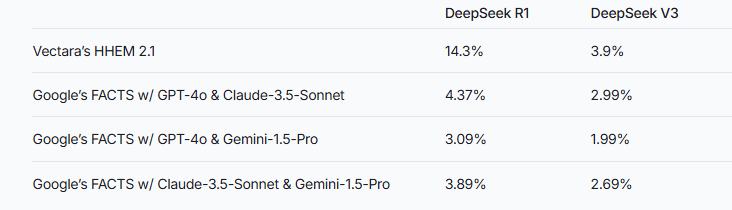
为全面评估这两款模型的表现,研究人员运用了Vectara的HHEM模型以及Google的FACTS方法来进行判断。其中,HHEM作为专业的幻觉检测工具,在检测DeepSeek-R1幻觉率增加方面,展现出了较高的灵敏度;而FACTS模型在这方面的表现则稍显不足。这似乎暗示着,相较于LLM作为标准,HHEM或许更为有效。
值得关注的是,尽管DeepSeek-R1在推理能力上表现优异,但其伴随的较高幻觉率不容忽视。这或许与推理增强模型需要处理的复杂逻辑存在关联。随着模型推理复杂性的提升,生成内容的准确性可能会受到影响。研究团队着重强调,如果DeepSeek在训练阶段能够更加注重减少幻觉问题,或许有望实现推理能力与准确性的良好平衡。
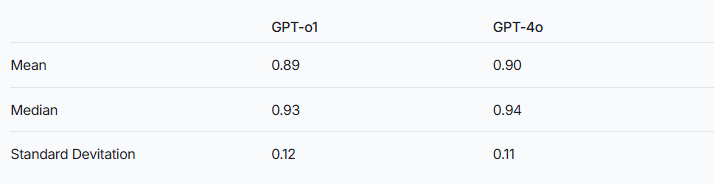
虽然推理增强模型普遍呈现出较高的幻觉率,但这并不意味着它们在其他方面毫无优势。对于DeepSeek系列而言,在后续的研究与优化过程中,解决幻觉问题以提升整体模型性能,仍是一项重要任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号