在当下的AI热潮中,DeepSeek成为备受瞩目的焦点,尤其在其开源并发布推理模型R1后,引发广泛关注与诸多争议。
随着DeepSeek的爆火,各种谣言甚嚣尘上。Stability AI曾经的研究主管Tanishq MathewAbraham以业内人士身份,对围绕DeepSeek的谣言进行有力反驳,并阐述其优势。
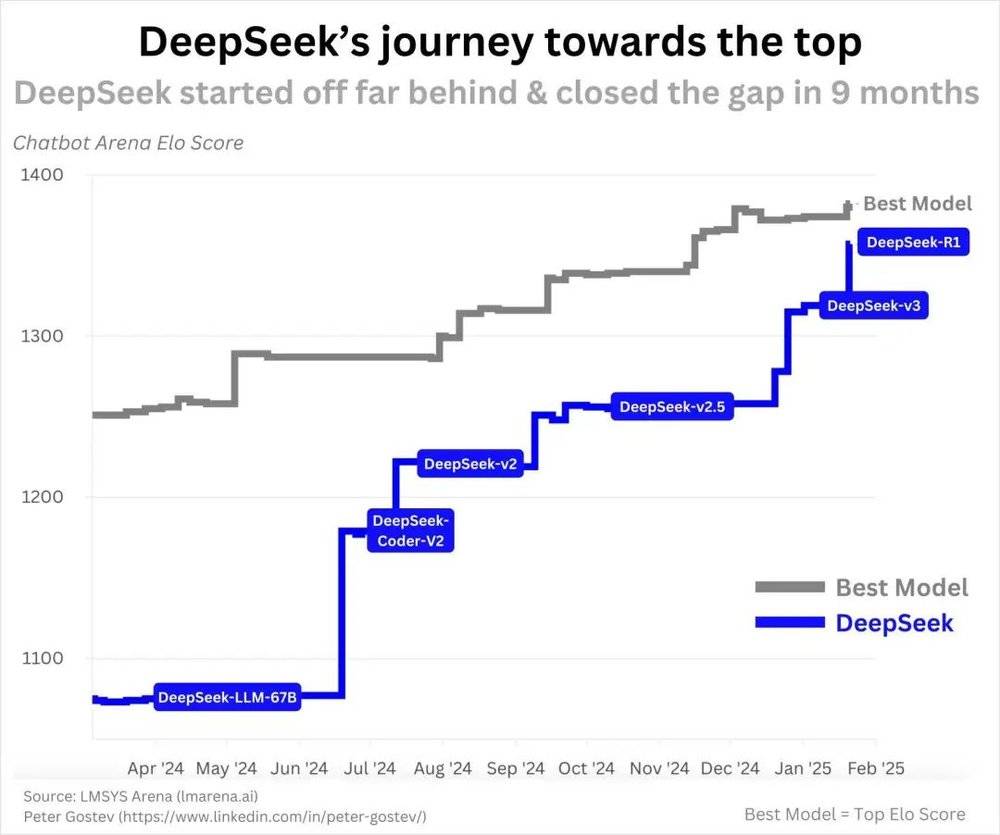
谣言一称DeepSeek是突然冒出的中国公司。实则到2025年1月,多数生成式AI研究人员已对其有所耳闻,且在完整版发布前几个月就发布了R1预览。DeepSeek首个开源模型DeepSeek-Coder于2023年11月发布,一年内持续推出成果直至R1,进步速度合理,并非一夜成功。
谣言二质疑模型成本非600万美元。DeepSeek-V3论文提及的成本在计算上存在不准确性,因未包含强化学习训练额外成本。众多分析基于多种因素得出类似估计,且DeepSeek成本基于当前市场价格估计GPU成本,实际GPU集群购入成本可能更低,同时还有实验成本、研究员薪资等未被报告,质疑其低成本运营性质是不公平的。

谣言三认为美国AGI公司浪费钱、看跌英伟达。尽管DeepSeek训练效率高,但更多计算资源并非坏事。Scalinglaws表明增加计算能力可提升性能,众多AGI公司押注此规律以实现AGI和ASI,获取更多计算能力是合理行动,DeepSeek并非看跌英伟达的理由。
谣言四称DeepSeek无有意义创新。实际上,DeepSeek在语言模型设计和训练方法上有诸多创新。如开发多头潜注意力 (MLA),这是MHA机制变体,节省内存且性能更佳;展示简单强化学习管道实现类似o1结果,开发更高效的GRPO算法;设计DualPipe技术,提升多GPU训练效率。并且,DeepSeek开源这些创新,让业界受益。
谣言五指责DeepSeek“汲取”ChatGPT知识。“蒸馏”概念在此使用不当,即便假设用ChatGPT生成文本训练,OpenAI也无证据。且使用其他来源的ChatGPT生成数据未被禁止,DeepSeek的成就不能因此被忽视。
在AI领域竞争格局中,中国人一直具备竞争力,DeepSeek的出现使其更无法被忽视。虽然美国一些公司有更好模型且将获充足计算能力保持领先,但中国也将加大投入,竞争日益激烈,而DeepSeek的R1无疑是令人印象深刻的模型。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号