近期,AI领域波澜起伏,DeepSeek的发展动态备受瞩目。政治学家、哈佛大学教授GrahamAllison在X上的提问引发广泛关注:“谁曾错失了DeepSeek”?原来,美国在AI人才竞争中经历了一次关键“失手”。
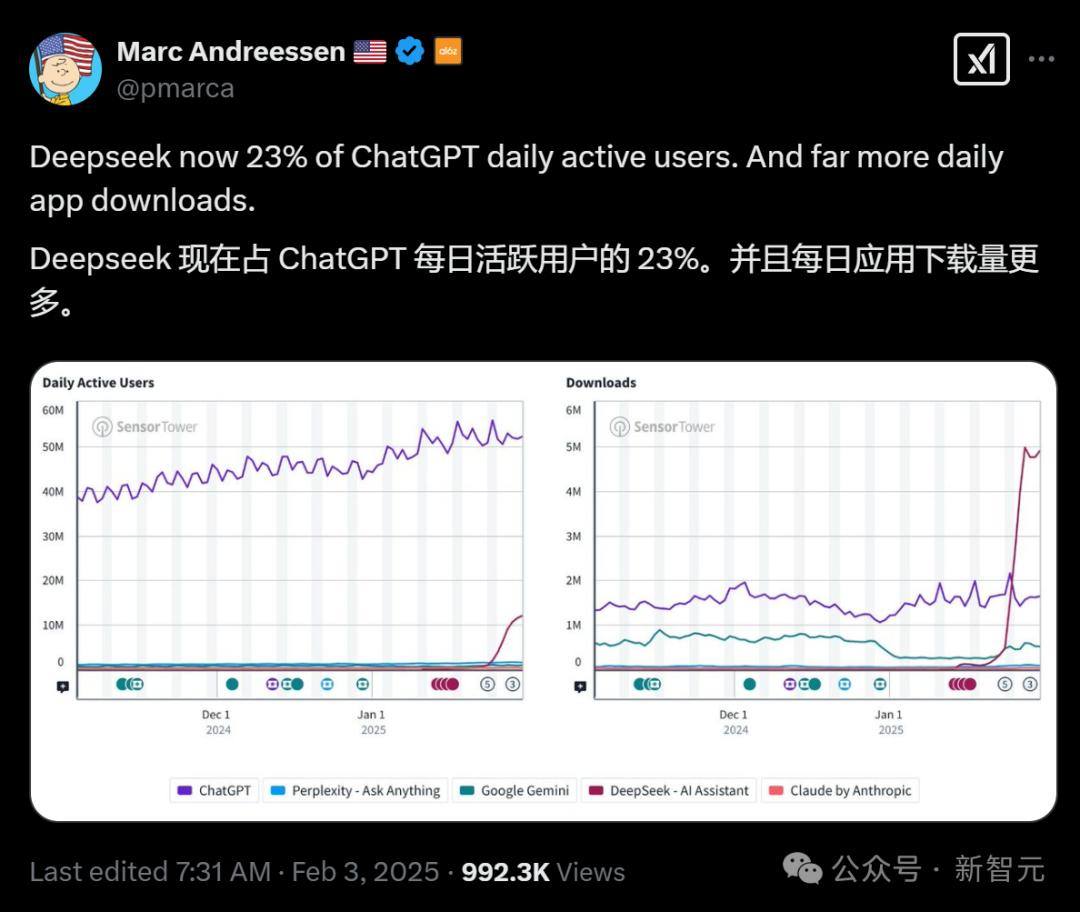
DeepSeek多模态团队的第4位工程师潘梓正,在开发DeepSeek的R1模型时发挥了重要作用。他曾在英伟达实习4个月,并拿到全职邀约,最终却选择归国加入DeepSeek。这一决定被GrahamAllison视为类似“钱学森归国”的“人才流失”,美国AI领域的主导地位也因此受到冲击,相关公司市值蒸发一万亿,全球AI格局被改写。
英伟达高级研究科学家禹之鼎透露,2023年夏季潘梓正实习时,DeepSeek多模态团队仅3人。潘梓正后来参与了DeepSeek-VL2、DeepSeek-V3等关键项目。他的经历体现出优秀人才的选择并非局限于美国公司,中国同样为他们提供了施展才华的舞台。

Lex Fridman的播客节目邀请了AI2的模型训练专家Nathan Lambert和Semianalysis硬件专家DylanPatel,深入探讨DeepSeek如何撼动全球格局。其中,DeepSeek是否使用OpenAI数据的争议备受关注。OpenAI曾称DeepSeek使用其模型蒸馏,然而大佬们一致认为这是OpenAI转移话题之举,因为多数公司都在未经许可下使用互联网数据训练。
在训练成本方面,DylanPatel指出,DeepSeek的低成本关键在于MoE和MLA(多头潜注意力)技术。MOE架构可将数据嵌入更大参数空间,训练或推理时仅激活部分参数,提升效率。DeepSeek模型参数超6000亿,每次仅激活约370亿个参数,远低于Llama405B。
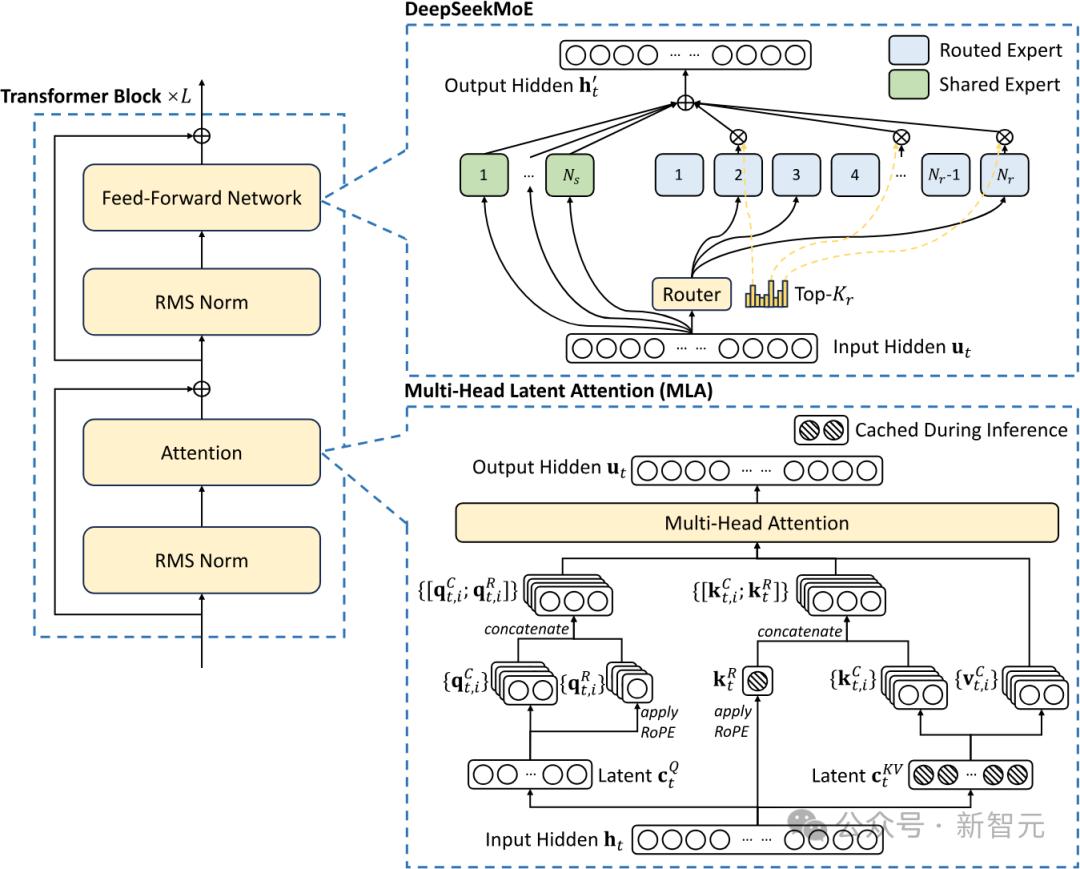
MLA则用于减少推理和训练过程中的内存占用,利用低秩近似数学技巧。DeepSeek还通过自行调度GPU通信,精细控制SM核心功能,进一步提高训练效率。这些创新使DeepSeek在高效语言模型训练方面领先。
在模型定价上,DeepSeekAPI远低于其他提供R1服务的公司。其创新的MLA机制能减少约80%到90%的注意力机制内存占用,有助于处理长上下文。此外,OpenAI较高的利润率也是服务成本差异的原因之一。
尽管美国在GPU等芯片领域领先,但中国在人才数量和工业能力上优势明显。中国的电力资源和工业规模庞大,构建大型数据中心的能力不容小觑。美国虽出台禁令限制中国AI发展,然而中国凭借自身实力,在AI领域的发展脚步并未停歇。
在对明星推理模型的实测中,谷歌的Gemini Flash Thinking虽性能价格兼具优势,但应用场景受限。DeepSeekR1展示完整思维链token的特点受到好评,相比之下,o3-mini表现较为平庸。DeepSeekR1作为低成本推理模型,其成就值得肯定,未来随着技术发展,AI模型推理成本有望持续下降,解锁AGI潜力。
对于AGI竞赛的最终赢家,谷歌因基础设施优势成为领跑者,OpenAI则在舆论和商业化方面领先。目前微软在AI领域实现盈利,其他公司仍在融资。未来,推理、代码生成等领域将成为AI竞争的关键,谁能把握机遇,谁就能在市场中脱颖而出。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号