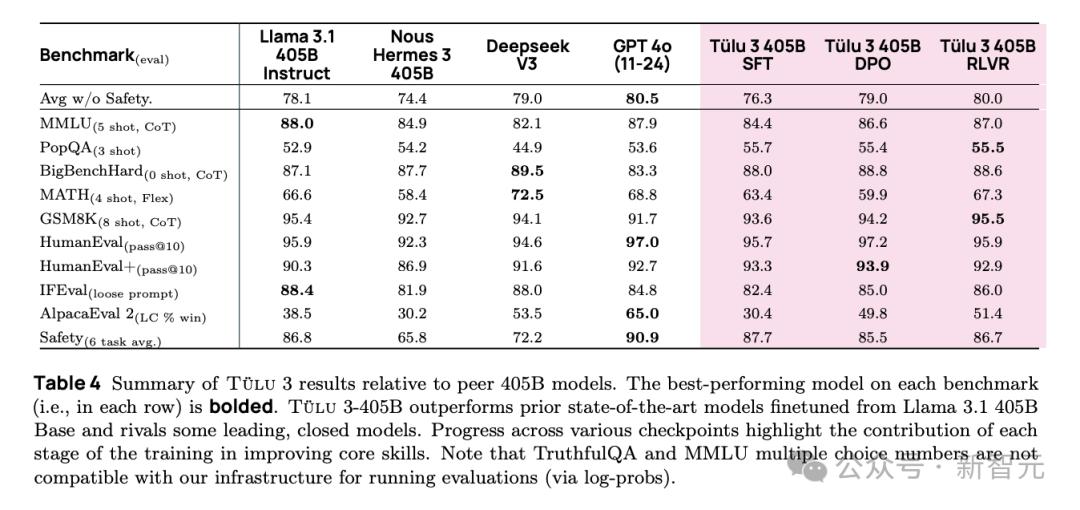
在模型竞争激烈的当下,美国艾伦人工智能研究所(Ai2)带来新惊喜,推出基于强化学习的新一代开源模型Tülu 3405B。此模型表现出色,在不少关键基准测试里,性能与Deepseekv3、[GPT-4](https://ai-kit.cn/sites/1023.html)o相当甚至更优,还超越了许多先前发布的同等参数规模的后训练开源模型,如Llama 3.1 405B Instruct和Nous Hermes3 405B。

回顾历程,2024年11月,艾伦人工智能研究所先推出Tülu 3 8B和70B,性能超越同等参数的Llama 3.1Instruct版本,并在论文中公开训练细节,涵盖训练数据、代码、测试基准等。而在今年1月30日,更为强大的Tülu 3 405B震撼亮相。
不过,Tülu 3405B并非完美无缺。在官网体验版测试时,对于经典的数“Strawberry中有几个r”的问题表现不佳,但在后续需要推理的问题上,能给出正确回答思路。并且在生成与蛇相关格言时,大多未能理解传统文化中“蛇”的寓意。对于想体验本地大模型的用户,Tülu3 8B和70B已支持ollama下载,405B预计也将尽快上线该平台。
Tülu3的独特之处,还体现在其“炼丹术”——全新的后训练框架上。早期语言模型后训练工作多遵循InstructGPT等开创的标准方法,而多数成功模型对训练数据等披露有限。Ai2却不同,不仅完整公开Tülu3的训练数据、方法和成果,其构建流程也别具一格,包含数据、训练和评估三部分。
Tülu 3项目从确定通用语言模型的关键期望能力起步,像知识、推理、数学等能力。模型训练在预训练语言模型(Llama 3Base)基础上,采用四阶段后训练配方。第一阶段是精心策划和合成式提示;第二阶段在混合数据集上进行监督微调,同时用攻击性提示词数据保障模型安全;第三阶段结合离线和在线策略偏好数据进行偏好微调;第四阶段采用新的基于强化学习的方法——可验证奖励强化学习(RLVR)。
这种新训练方法针对可验证结果的任务,通过明确问题完成情况更新策略函数。有趣的是,在更大规模(如405B)上,可验证奖励强化学习框架对数学性能提升更显著。训练Tülu3405B时使用32个节点(256个GPU)并行运行,推理时可用vLLM部署模型。受计算成本限制,超参数调整受限,训练遵循“参数更大的模型采用较低学习率”原则。
总体而言,Tülu3采用全新后训练框架,涵盖完全开源的数据、评估、训练代码及开发配方,性能超越同尺度模型。它标志着开放后训练研究的新里程碑,为后续研究提供借鉴,其训练方法值得开发者深入探索。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号