在DeepSeek和o1/o3等推理大模型不断带来震撼表现之时,有研究开始聚焦于这些模型的弱点。来自腾讯AI实验室、苏州大学和上海交通大学的研究团队,以开源的DeepSeek-R1和QwenQwQ系列模型为主要研究对象,展开了深入探索。
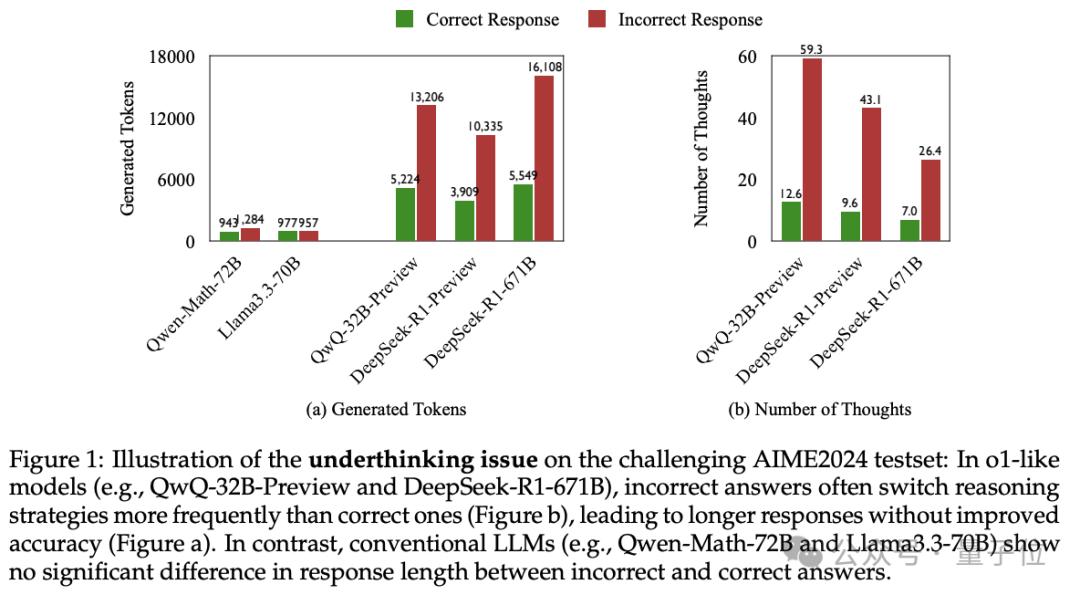
研究揭示,当遇到高难度问题时,推理大模型会像“三心二意的学生”,频繁切换解题思路,出现Underthinking(欠思考)现象。这一现象在解决数学竞赛题等复杂任务时尤为明显。例如,在处理一些数学问题时,模型虽在思考早期走上正确路线,却倾向于“浅尝辄止”,很快转向其他思路,导致后续生成的大量tokens对解题毫无帮助,既浪费计算资源,又降低答案正确率。
为系统分析这一情况,团队在MATH500、GPQADiamond和AIME2024等具有挑战性的测试集上对类o1模型QwQ-32B-Preview、DeepSeek-R1-671B等进行实验。结果显示,类o1模型在错误回答中比正确回答多消耗225%的token,思维切换频率增加418%。研究团队还开发评估框架判断被放弃的推理路径能否推出正确答案,发现超70%的错误回答至少包含一个正确思路,超50%的错误回答中有10%以上思路正确。基于这些观察,团队提出用于量化Underthinking程度的指标UnderthinkingMetric。

理解思维不足现象对开发高效推理模型至关重要。为此,研究者借鉴人类考试策略,提出“思路切换惩罚机制”(Thought SwitchingPenalty,TIP)。其原理是对触发思路切换的关键词施加惩罚,降低其在解码过程中的生成概率,迫使模型在当前路径探索更久。实验表明,加入TIP能提升模型数学测试准确率,降低UTScore,且无需重新训练模型,仅调整解码策略,实用价值显著。
与此同时,UC Berkeley教授Alex Dimakis分享类似观察,即错误答案更长,正确答案更短。基于此,他们提出“简洁解码”(Laconicdecoding)方法,并行运行5次模型,选择tokens最少的答案。初步实验显示,简洁解码在AIME2024测试上能提高6%-7%的准确率,比ConsensusDecoding更好更快。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号