在AI领域的激烈角逐中,DeepSeek脱颖而出,引发全球关注。知名投资人“木头姐”凯茜·伍德称其加剧了人工智能的成本崩溃,这一“神秘的东方力量”不仅让行业内众多从业者为之侧目,更引发了关于中美AI领导地位更替的思考。
DeepSeek的颠覆性创新,体现在极致的效率革命上。1月20日发布的DeepSeek-R1模型系列表现亮眼,在大模型排行榜ChatbotArena上,DeepSeek-R1的基准测试排名升至全类别第三,与Chat[GPT-4](https://ai-kit.cn/sites/1023.html)o最新版不相上下,在风格控制类模型分类中还与OpenAI-o1并列头名。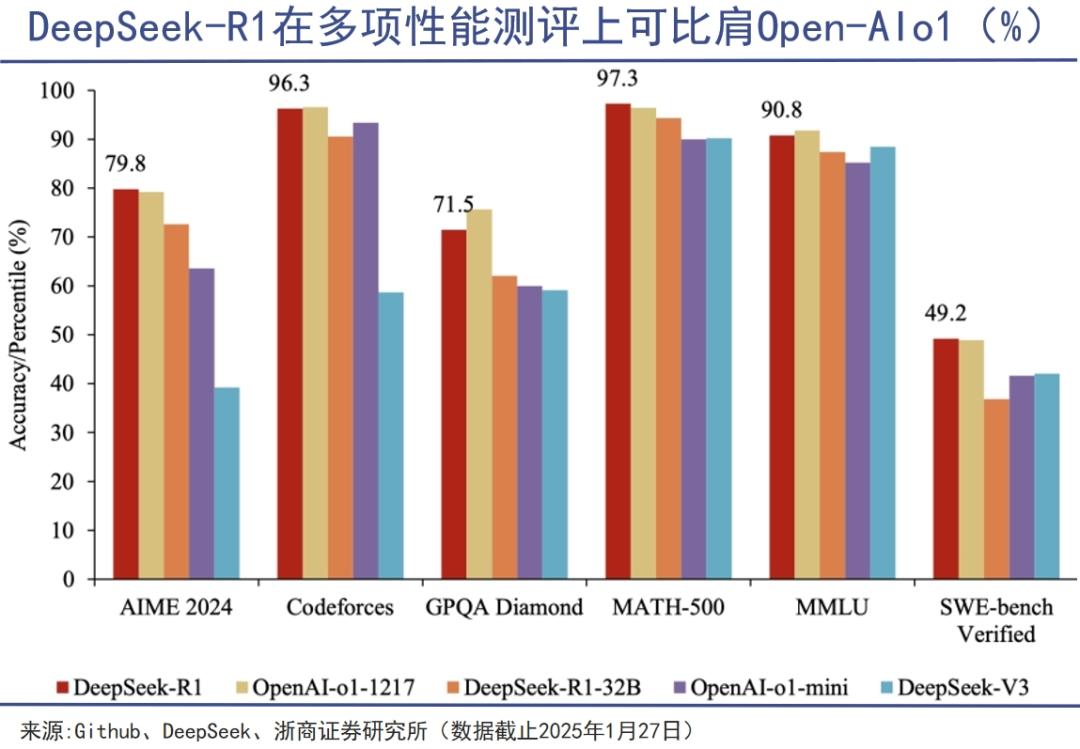
虽R1模型训练成本未公布,但参考DeepSeekV3技术报告,V3模型训练只需278.8万GPU小时,成本仅557.6万美金。传言R1模型训练成本与之相当,可参数规模达6710亿。相比之下,GPT-4o模型训练成本约1亿美元,MetaLlama 3系列模型训练需要3930万H100 GPU小时,DeepSeek训练成本仅约为Llama3的7%。这家中国初创AI公司仅用不到十分之一的成本,就达到世界一流水平。
DeepSeek“四两拨千斤”的能力,得益于其自研的MLA和MOE架构,大幅降低了模型训练成本。此外,R1模型采用数据蒸馏技术,对原始数据去噪、降维、提炼,提升训练效率。这就好比DeepSeek用更高效的学习方法取得好成绩,而OpenAI还在依赖“题海战术”。
半导体领域遵循摩尔定律,AGI行业则依据ScalingLaw发展,即模型性能与规模呈正相关。然而,DeepSeek的出现打破了这一定律,至少让ScalingLaw的边际效益放缓。这启示人工智能产业不再单纯追求大规模算力投入,而是要在模型架构和工程优化上寻求突破。
DeepSeek带来的“范式转移”,破除了科技大厂的技术壁垒和重资本比拼的惯例。它不仅开源还免费,引得OpenAI紧急上线新一代推理模型o3系列的mini版本,并首次免费开放基础功能。奥特曼也承认在开源问题上需调整策略。
尽管DeepSeek改变了超大规模扩张算力的行业路径,但就此认为应彻底放弃算力建设还为时尚早。我国算力基础设施尚处初步搭建阶段,远未过剩。一方面,DeepSeek用户量激增,其深度思考和联网搜索功能出现宕机,移动应用下载量可观。另一方面,DeepSeek目前功能有限,未来拓展图片、音频和视频生成领域,对算力和训练成本的需求将大幅增长。
目前,算力建设已上升为国家级战略。我国算力基础设施规模占全球26%,位列第二。根据规划,到2025年,我国算力规模将进一步提升。“东数西算”工程稳步推进,国内智算中心建设蓬勃发展,国产芯片厂商也迎来发展机遇。
DeepSeek的成功,体现了中国在资源有限的条件下,以低成本开发优质产品的智慧与韧性。在中美AI竞争中,中国企业虽有突破,但仍需保持冷静与谦逊,而算力基础设施始终是AI发展的重要支撑。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号