2月3日晚,五位高校教授齐聚线上,深入探讨DeepSeek的技术奥秘与未来走向。此次分享会聚焦于DeepSeek的模型方法、框架、系统及基础设施等核心领域,全面剖析其技术原理,并展望未来发展方向。
复旦大学教授邱锡鹏深入解读了R1技术路线图,强调强推理模型最终将落脚于Agent。他指出,在强化学习框架下,大推理模型包含策略初始化、奖励设计、搜索和学习四个关键要素。R1模型通过四个阶段的精心构建,成功复现了OpenAIo1的深度推理能力,这一成果为行业发展提供了重要参考。

清华大学长聘副教授刘知远认为,DeepSeek-R1的训练流程亮点显著。一方面,基于DeepSeek-V1基座模型,通过大规模强化学习得到R1-Zero;另一方面,强化学习技术成功泛化到其他领域,实现了推理能力的跨任务泛化。他强调,DeepSeek-R1的意义类似于2023年的MetaLlama,通过开源复现推动了行业发展。
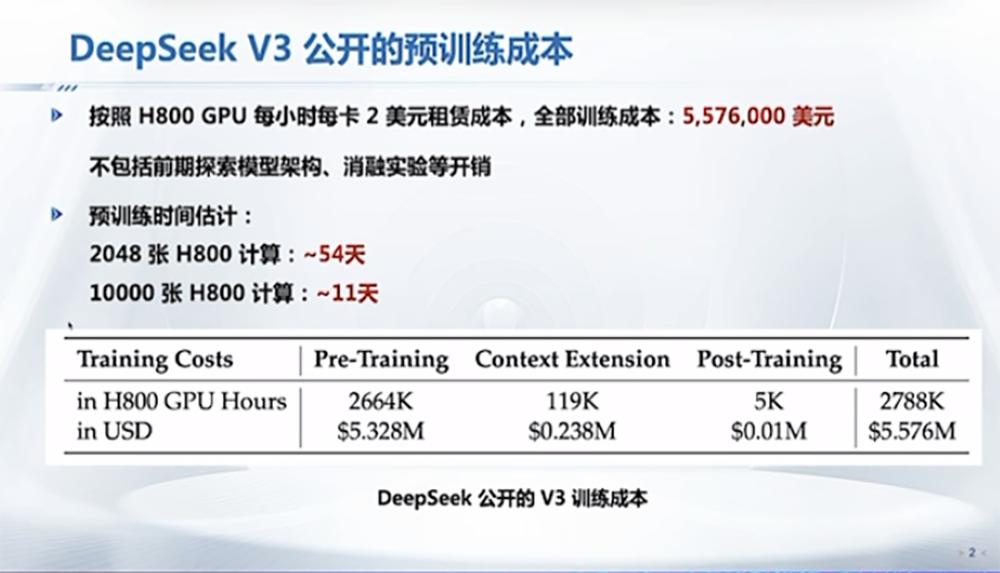
清华大学教授翟季冬详细拆解了DeepSeek的并行训练策略,以降低成本为核心,从负载均衡、通信优化、内存优化和计算优化四个方面进行深入分析。他指出,DeepSeek团队通过创新策略和精细优化,充分挖掘了算法、软件和硬件的协同潜力,为降低模型训练成本提供了有效途径。
上海交通大学副教授戴国浩围绕DeepSeek在软硬件上的优化展开讨论,特别是针对绕过CUDA层的技术进行了深入剖析。他认为,PTX优化可实现对底层硬件的更好编程和调用,通过底层优化和协同优化,有望进一步提升大模型性能,为实现“模型-系统-芯片”闭环发展奠定基础。
在互动环节,教授们就DeepSeek的亮点技术、R1模型出现的时机、对中国大模型发展的启示以及MoE架构等热点问题展开了热烈讨论。他们一致认为,DeepSeek的成功为中国大模型发展提供了宝贵经验,鼓励更多团队勇于创新,积极探索未来发展方向。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号