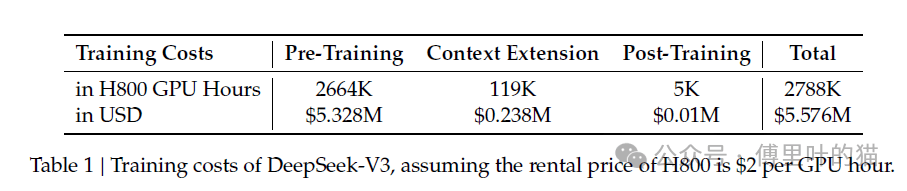
近期,DeepSeek成为关注焦点。虽其战绩出色,但网上关于其成本等说法存在夸大。DeepSeek仅在论文提及训练成本为557.6万美元,这并非总成本。
在GPU配置方面,DeepSeek-V3使用2048块H800GPU训练。与之对比,Meta使用超16000块GPU的集群。由于芯片禁运,DeepSeek的H100 GPU数量少于Meta,且H800性能逊于H100。
网络带宽上,H100配备HBM3高带宽内存,互联带宽最高900GB/s,数据传输高效;H800的NVLink带宽最高400GB/s,数据传输速度受限。
显存带宽方面,H100能快速在显存和处理器核心间传输数据,提升计算效率;H800的显存带宽降低,数据读取写入速度较慢。
算力上,H100基于Hopper架构,FP8算力可达1 exaFLOPS,能快速处理计算任务;H800算力被阉割,完成计算耗时更长。
因幻方(DeepSeek)未公布GPU数量,外界根据其他数据估计,其拥有的GPU数量约为2万至5万个(以A100为基准),虽低于Meta规模,但仍是计算资源丰富的机构之一。
大模型训练存在风险,GPU资源宝贵,长时间占用训练模型风险高。如OpenAI的Orion项目耗时超3个月训练,而快速迭代小型模型更具灵活性。
模型开发实验计算量高于最终报告数字,语言模型实验室会通过scalinglaws降低预训练风险。据推测,DeepSeek-V3的预训练实验总计算量可能是论文报告数字的2至4倍,且可能使用其他项目增加计算开销。
计算资源成本估算需考虑多因素。DeepSeek是否拥有或租用GPU不明,若拥有,总拥有成本包括硬件采购、电力消耗等。1万块以上A/H100GPU集群,电费每年可能超1000万美元,单块H100市场价约3万美元,1万块H100资本支出可能超10亿美元。
此外,DeepSeek可能与云服务提供商合作,即便如此,仅计算资源成本每年也可能达数亿美元。除硬件成本,DeepSeek-V3成功离不开庞大技术团队,其论文有139名技术作者,人员成本每年可能超1000万美元。
结合硬件、电力和人员成本,DeepSeek AI一年运营成本不低于5亿美元,SemiAnalysis估算为13亿美元,远高于论文中的550万美元估算。
与其他公司对比,尽管DeepSeek-V3成本高于开源模型,但从行业看,投入仍合理。Meta和OpenAI等美国科技公司在AI模型开发上年均投入接近或超100亿美元,DeepSeek-V3成本更经济高效。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号