近期,来自中国的生成式人工智能系统DeepSeek在全球引发热议。发布仅18天,其下载量高达1600万次,几乎是同期竞争对手OpenAI的ChatGPT两倍,尽显强大市场吸引力。1月26日,DeepSeek应用程序登顶苹果AppStore并持续领先,在140个国家的苹果App Store及美国Android Play Store下载榜均居首位。
DeepSeek能获此关注,除性能出色,低训练成本是关键。早在2024年8月,团队发表论文介绍新型负载均衡器,为解决混合专家(MoE)模型中专家负载不均衡问题,提出无损平衡(Loss-Free Balancing)策略,此乃无辅助损失的负载平衡策略。通过动态更新专家偏见,实现专家负载均衡分布,还提升了模型性能上限。
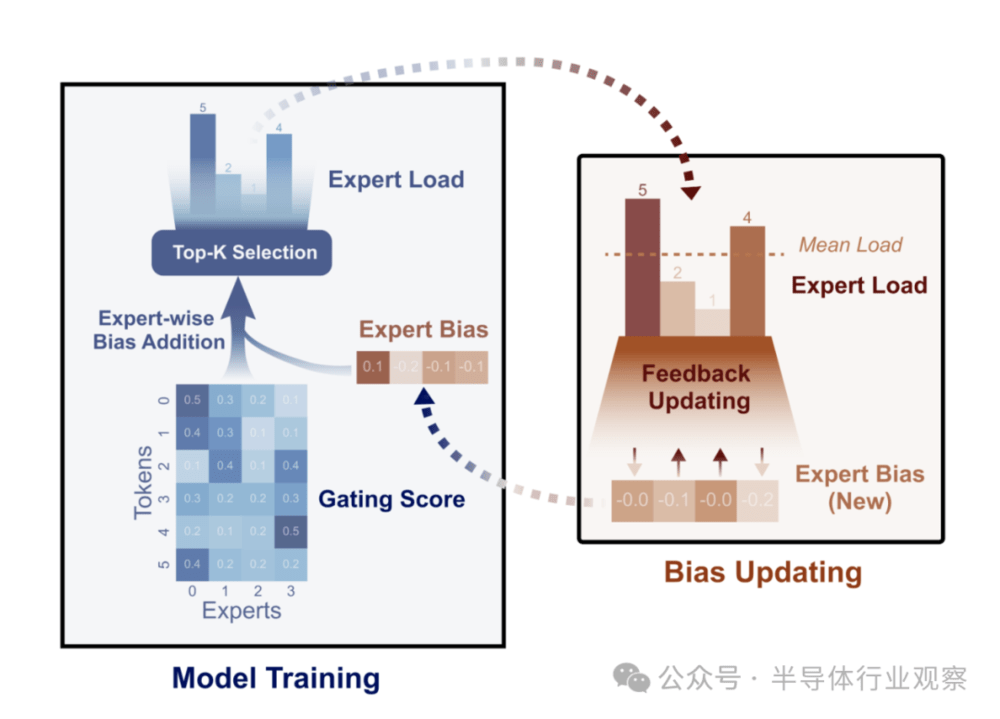
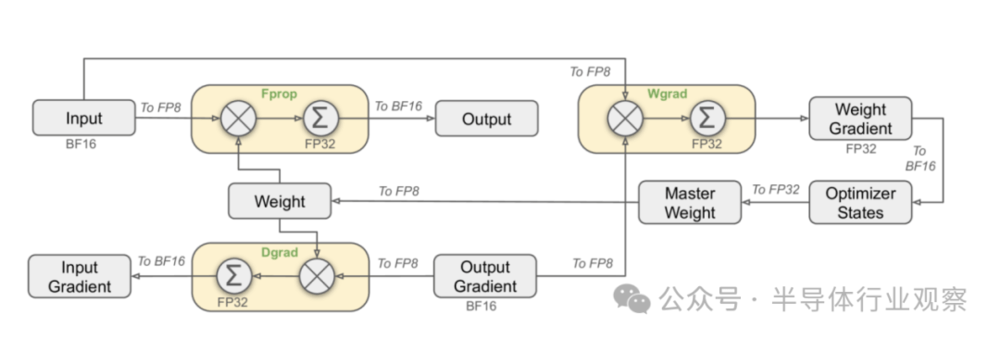
2024年底报告《DeepSeek-V3 TechnicalReport》深入解读了DeepSeek-V3模型技术架构。团队追求模型性能强、成本低,架构上采用多头潜在注意力(MLA)和DeepSeekMoE进行高效推理与训练。支持FP8混合精度训练,优化训练框架,设计DualPipe算法实现高效流水线并行,减少流水线气泡,通过计算-通信重叠隐藏通信开销,还开发跨节点全对全通信内核,优化内存占用,实现高训练效率。
1月20日,DeepSeek推出DeepSeek-R1模型,增加强化学习与监督微调阶段增强推理能力,收费比V3模型高出6.5倍。随后发布Janus-Pro多模态模型,改进训练策略等,增强多模态理解与文本到图像生成能力。
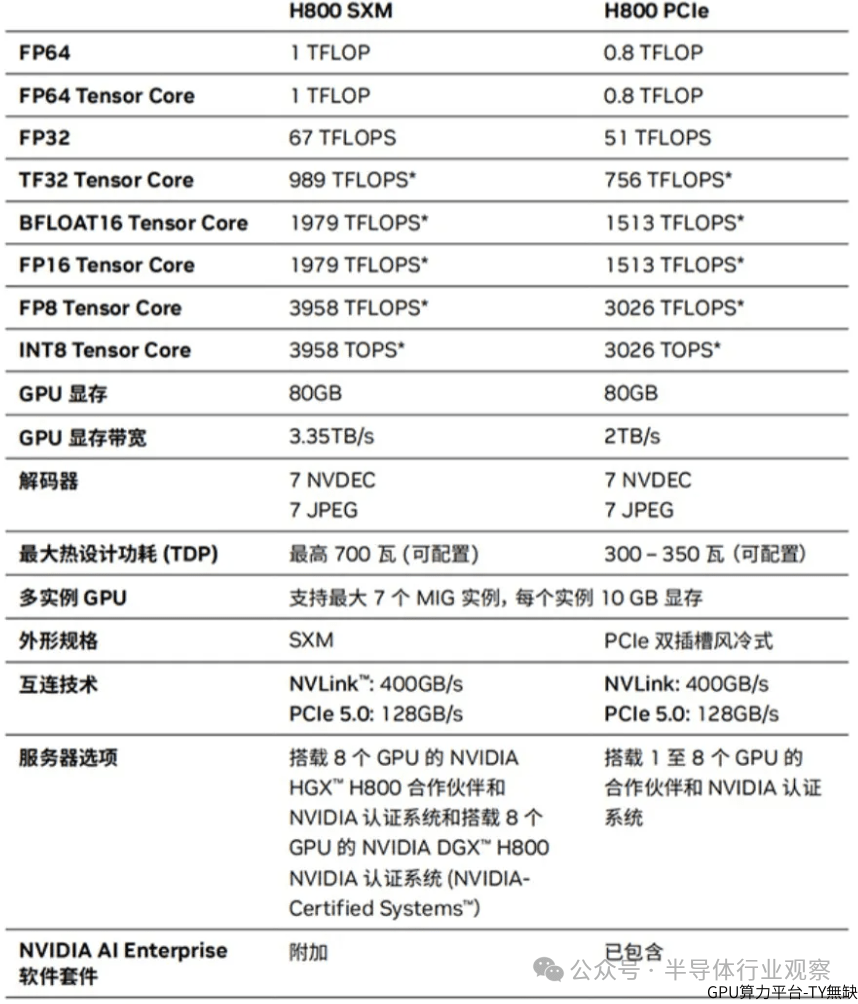
DeepSeek的极低训练成本震动AI芯片市场。训练V3模型的集群有256个服务器节点,每个节点8个H800GPU加速器。H800是英伟达应美国出口限制推出的GPU,DeepSeek使用的H800SXM5版本通过NVLink和NVSwitch互连技术实现GPU间高带宽连接,适合规模化部署。
外国分析师对DeepSeek看法不一。nextplatform分析师认为其采取多种优化方法提高了训练和推理性能,创建了GPU虚拟DPU,DualPipe算法提升计算效率。SemiAnalysis虽质疑成本,但承认其有创新。DeepSeek-R1能快速取得成果,得益于推理新范式,该范式通过合成数据生成和现有模型后训练中的RL实现推理能力,降低成本。
此外,DeepSeekV3采用多token预测(MTP)技术提高模型性能,设计“门控网络”高效路由token,提升训练效率、降低推理成本。强化学习对R1模型也有重要作用。MLA技术更是大幅降低推理成本,减少KV缓存量。
DeepSeek爆火引发英伟达股价波动。Nvidia虽积极评价其进展,但“木头姐”、CounterpointResearch分析师等认为DeepSeek挑战了传统观念,威胁英伟达增长战略。DeepSeek采用性能低、价格廉的芯片,且绕过英伟达CUDA使用PTX编程,引发担忧。不过,也有观点认为人工智能GPU需求仍超供应,DeepSeek的突破为人工智能进入廉价设备提供途径。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号