春节假期,DeepSeek相关资讯持续刷屏。1月20日,中国科技公司深度求索推出推理模型DeepSeek-R1,仅用OpenAI十分之一的成本就达到其最新模型GPT-o1同级别的表现。此前,深度求索推出的DeepSeek-V3仅花费558万美元,不到国外公司十分之一的GPU芯片和训练时长,就实现了与[GPT-4](https://ai-kit.cn/sites/1023.html)o和ClaudeSonnet 3.5等顶尖模型相当的性能,这一消息激起全球科技界关注。
DeepSeek-R1发布后的十天内,先后登上中国、美国等70多个国家苹果应用商店下载榜榜首,首次超越OpenAI的ChatGPT,引发美国科技公司关注,同时也引发了华尔街恐慌,1月27日,美国主要科技股市值开盘缩水超1万亿美元。
DeepSeek背后的深度求索是一家创立于2023年的年轻公司,但其母公司幻方量化是管理了超过1000亿元资产的国内头部量化交易公司,在多年前就开始涉足AI研究。DeepSeek创始人梁文锋最早开启AI研究的初衷是用GPU计算交易仓位,训练量化交易模型,此后囤积了过万块先进GPU芯片开始训练AGI模型,为DeepSeek日后的模型进展打下了基础。
DeepSeek曾以带头打响大模型价格战而在国内AI行业引发关注。2024年5月,DeepSeek发布DeepSeek-V2,价格仅为GPT-4-Turbo的近百分之一。此后一年内3次降价,每次降幅超过85%。其研究人员提出的一种新的MLA(一种新的多头潜在注意力机制)架构,与DeepSeekMoESparse (混合专家结构)结合,把显存占用降到了其他大模型最常用的MHA架构的5%-13%。
DeepSeek通过“数据蒸馏”技术,把数据计算最大程度降低,仅用1/5的数据量达到同等效果,促成了成本的下降。DeepSeek-R1会先判断问题类型,再精准调用对应模块,让模型响应速度提升3倍,能耗也更低。R1的预训练费用只有557.6万美元,在2048块英伟达H800GPU集群上运行55天完成。
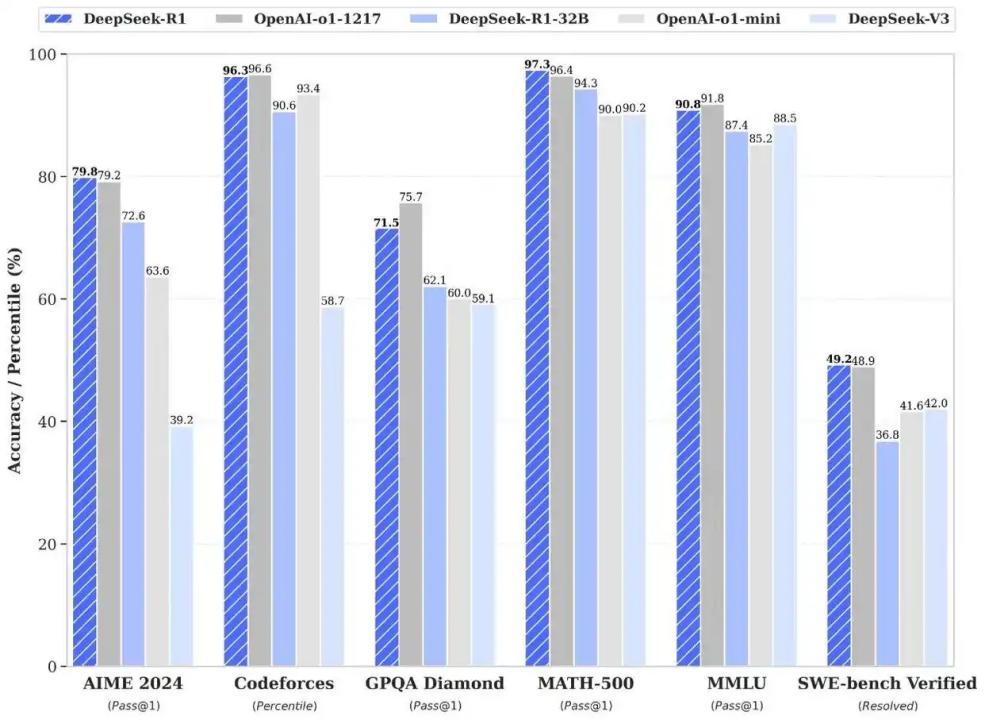
多位行业人士将DeepSeek的脱颖而出理解为“模块化特种兵”,在与OpenAI等“通用巨兽”的比赛中,在部分领域展现出同等能力甚至略微领先。DeepSeek跳过了美国开发者们认为必不可少的步骤,为中国乃至世界各地的AI创业公司提供了弯道超车的可能。
DeepSeek引起轰动,除了模型本身的优异表现,还来自其坚持的免费开源主张,公开模型的源代码、权重和架构。这一决策得到了许多行业专家和投资者的赞许。OpenAI最初旨在开源,但在GPT-3发布,接受微软投资后走向闭源。Meta的Llama号称开源,但存在诸多限制。大多数中国大公司开发的大模型选择了闭源路线。
DeepSeek选择开源,既是出于对传统大厂的技术垄断的挑战,也是基于自身发展情况的考量。其模块化模型设计难以被简单复制,越多的用户和开发者使用,则意味着模型得到更多训练。当下,DeepSeek背靠千亿量化基金,选择只做模型研究,通过开源基础模型吸引开发者,未来再逐步推进商业化。
在AI竞争格局下,开源不仅是技术策略,更是参与制定行业规则的关键落子。这本质上是一场关于“标准制定权”的争夺,DeepSeek代表的中国科技公司给出的方案是创新。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号