大模型预训练的“成本命门”:优化器效率
2014年提出的Adam及其改进版AdamW,长期是开放权重语言模型预训练的主流优化器——它能帮助模型在海量数据中保持稳定训练,同时加快收敛速度。但随着模型规模飙升至十亿级,预训练已成为计算成本最高的环节之一:优化器的设计直接决定训练效率与成本投入。
近年来,Muon、Soap、Kron等矩阵型优化器声称能“显著加速”,部分方法宣称比AdamW快1.4-2倍。但斯坦福大学Percy Liang团队的最新研究指出:这些结论可能存在方法论缺陷——要么超参数调优不公平,要么短期评估误导,导致AdamW的真实性能被低估。
两大误区让优化器评估“失真”
研究团队梳理了此前优化器对比实验的核心问题:
- 超参数调优不公平:常用的AdamW基线往往“调优不足”——仅调整学习率这一个参数,就能让1.3亿参数模型的训练速度提升2倍;而不同优化器的最优超参数差异极大(比如Lion需要0.6的权重衰减,远高于AdamW的0.1),固定共享超参数会让比较失去公平性。
- 短期评估误导性强:仅用短时间训练窗口评估性能不可靠——随着训练推进和学习率衰减,不同优化器的损失曲线会多次交叉,性能排名可能逆转。比如部分优化器初期快,但后期被AdamW反超。
三阶段实验还原“真实加速比”
为纠正这些误区,团队设计了系统性对比实验:覆盖11种主流优化器(包括AdamW、NAdamW、Muon、Soap等),测试1亿到12亿参数的模型规模,以及1倍到8倍Chinchilla数据比例,并为每个优化器进行独立超参数调优(用坐标下降法扫描学习率、权重衰减、预热步数等8个参数)。
实验分三阶段展开:
- 阶段I:全面参数扫描:对1.3亿、3亿、5亿参数模型,在1倍到8倍Chinchilla数据量下,扫描所有超参数的最优配置,发现不同优化器的最优参数差异极大,盲目迁移会导致结果不公。
- 阶段II:敏感参数识别:针对学习率、预热长度等随模型规模变化的敏感参数进一步优化,通过缩放定律计算加速比,还原优化器真实性能。
- 阶段III:案例研究:测试12亿参数模型和16倍Chinchilla数据比例,验证超参数拟合效果,探索优化器局限。
三大结论重新定义优化器选择
实验得出三个关键结论,彻底刷新了对优化器的认知:
- 独立调优是公平比较的前提:优化器的最优参数无法迁移——若不独立调优,新优化器的实际加速效果远低于声称值(比如部分方法声称快2倍,但实际仅快10%)。
- 长期评估才能反映真实性能:短期快不代表长期好——部分优化器初期损失下降快,但后期学习率衰减后,损失曲线会被AdamW追上甚至反超。
- 矩阵方法是速度“天花板”:所有最快的优化器都采用基于矩阵的预条件子(而非传统逐元素标量缩放)。Muon、Soap、Kron等方法,相比调优后的AdamW,能实现30%-40%的单步训练加速。
最优选择取决于“场景”
有趣的是,优化器的表现与具体场景强相关:
- 在标准Chinchilla数据比例(模型与数据量匹配)下,Muon性能最佳;
- 当数据量是Chinchilla比例的8倍以上时,Soap更优——高数据比例下,Soap的二阶动量更有效。
矩阵型优化器的“局限”
研究也揭示了矩阵型方法的潜在不足:
- 加速比随模型规模增大而衰减——12亿参数模型上,Muon的加速比降至1.2倍以下;
- 高数据比例下优势缩小——16倍Chinchilla数据量下,Soap在3亿参数模型上超过Muon,NAdamW也能追上。
研究信息与资源
- 论文标题:Fantastic Pretraining Optimizers and Where to Find Them
- 论文地址:https://www.arxiv.org/pdf/2509.02046v1
- Github:https://github.com/marin-community/marin/issues/1290
- 博客:https://wandb.ai/marin-community/marin/reports/Fantastic-Optimizers-and-Where-to-Find-Them–VmlldzoxMjgzMzQ2NQ
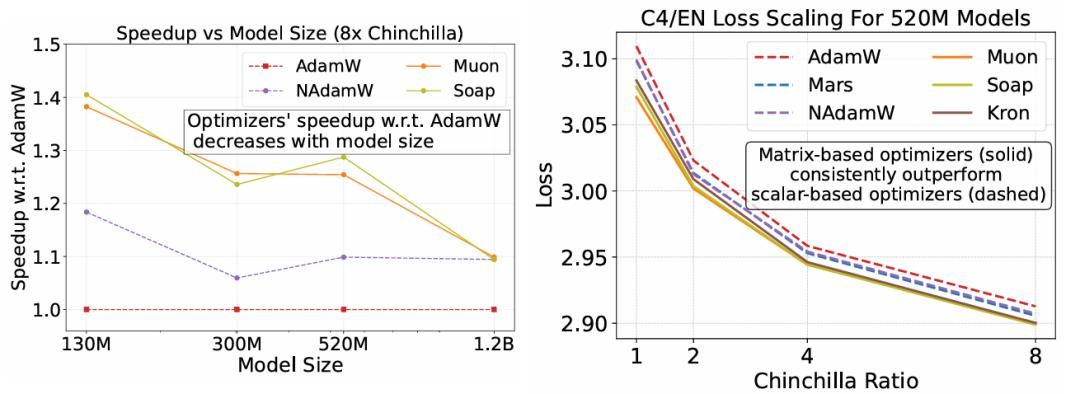
左:加速比随模型规模增大而衰减——12亿参数模型上,部分优化器的加速比降至1.1倍;右:矩阵型优化器(Kron、Soap、Muon)的损失曲线始终优于标量型(AdamW、NAdamW)。
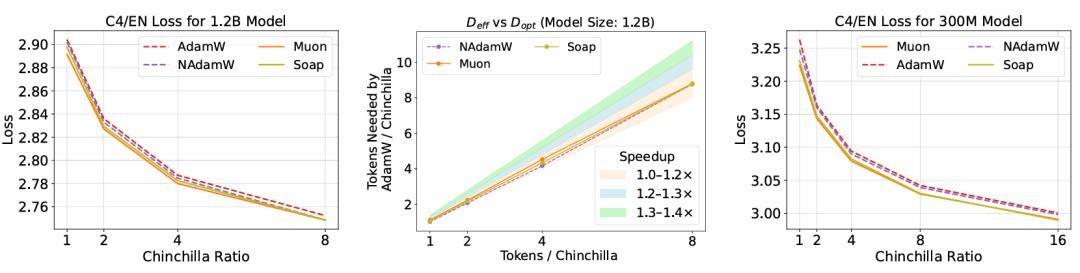
左:12亿参数模型上,Muon、Soap仍比AdamW快,但加速比降至1.2倍以下;右:16倍Chinchilla数据量下,Soap在3亿参数模型上超过Muon。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号