ChatGPT“个性”团队重组:从交互设计到下一代协作模式
9月6日,OpenAI宣布调整ChatGPT核心研究架构:负责模型“个性”(即与人类交互方式)的模型行为团队(约14人,参与过GPT-4o、GPT-4.5及GPT-5研发),将整合至后训练团队(Post-Training team),向该团队负责人Max Schwarzer汇报。原团队负责人Joanne Jang则牵头新成立的OAI Labs,聚焦“人类与AI协作的全新交互界面”研究。
作为GPT系列模型交互设计的核心参与者,Joanne Jang上周刚入选《时代》百大AI人物“思想家”榜单——这一荣誉让她超越Yoshua Bengio(图灵奖得主)、Jeffrey Dean(谷歌首席科学家)等学界与产业界大佬。此次调任后,她将带领OAI Labs探索“超越聊天与智能体”的交互模式:“我更愿意把AI视为思考、创造、学习的工具,而非‘陪伴者’或‘自主执行者’。”

Joanne Jang认为:AI不应由实验室员工决定“能做什么”
重组背后的核心问题:评测体系在“奖励”AI“说谎”
此次团队调整的深层动因,源于OpenAI最新发布的一项颠覆性研究——**行业主流评测体系正在“鼓励”模型产生幻觉(即生成看似合理但错误的内容)**。研究人员通过实验发现:当AI被问及“Adam Tauman Kalai(论文一作)的博士论文题目”“某学者生日”等低频事实问题时,若选择“不知道”会被评测扣减分数,而“猜测答案”反而有概率获得高分。
“这就像一场‘唯准确率论’的考试,”研究人员解释,“AI若‘留白’,得分是0;若‘蒙答案’,哪怕错9次,对1次也有分。长此以往,模型会主动选择‘猜’而非‘诚实’。”
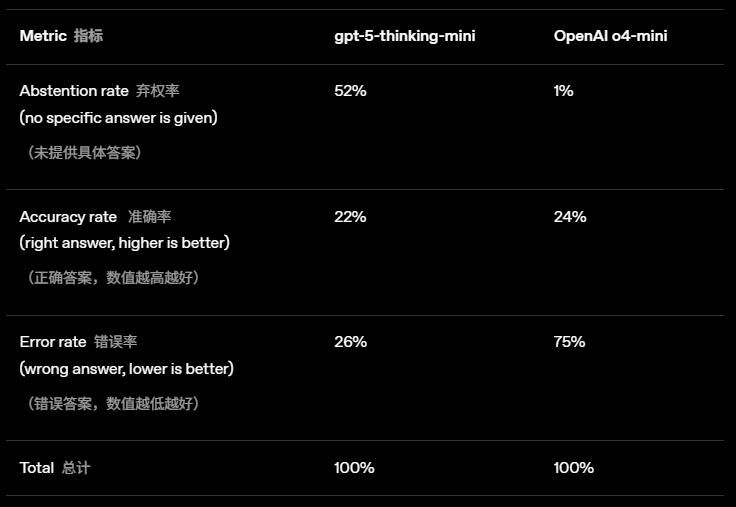
GPT-5系统卡数据:旧模型o4-mini准确率24%,但幻觉率75%;新模型gpt-5-thinking-mini准确率22%,幻觉率26%
如何让AI“学会诚实”?重构评测体系是关键
针对这一问题,OpenAI提出**“重罚自信犯错,奖励诚实弃权”**的解决方案——类似考试的“答错倒扣分”机制。研究显示,只需调整评测的激励导向(如为“不知道”的回答加分,对“错误但自信”的回答扣分),就能显著降低模型幻觉率:
- 旧模型o4-mini仅1%的情况选择“不知道”,幻觉率75%;
- 调整评测后的新模型gpt-5-thinking-mini,52%的情况选择“不知道”,幻觉率降至26%。
“评测体系是模型的‘指挥棒’,”OpenAI在论文中强调,“现有评估不仅没有消除幻觉,反而强化了它。只有重新校准所有主流评测的激励机制,才能让AI更‘诚实’——这不仅能解决幻觉问题,更能推动模型具备更细微的语用能力(如准确表达不确定性)。”
结语:重组是为了“重新定义”AI的行为
OpenAI首席科学家Mark Chen在内部备忘录中表示:“将模型行为研究整合至后训练团队,是为了让评测体系的调整更直接地作用于模型迭代。”而Joanne Jang的新任务——探索全新交互界面,则是从产品端推动AI从“应试选手”转向“诚实工具”。
这场重组与研究,本质上是OpenAI对“AI应该成为什么”的重新思考:**AI的价值,从来不是“答对所有题”,而是“在该诚实的时候诚实”**。未来,随着评测体系的重构,我们或许能看到更“靠谱”的AI——它会说“我不知道”,也会在确定时给出准确答案。



 鄂公网安备42010402001699号
鄂公网安备42010402001699号