认识AnyText:一款先进的多语言视觉文本处理工具
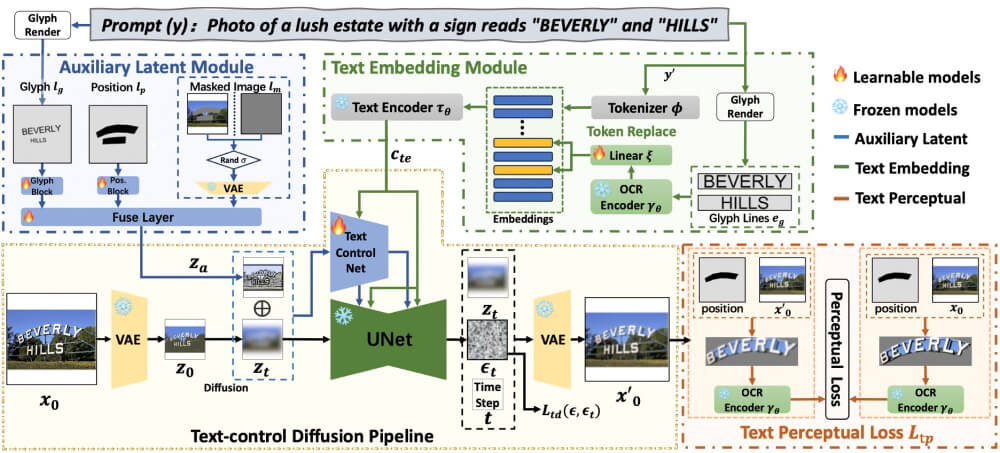
AnyText是由阿里巴巴智能计算研究院团队最新推出的一项创新技术,它是一个采用了先进的扩散机制的多语言视觉文本生成及编辑模型。该模型的核心目标是在图像中实现精确和流畅的文本渲染。AnyText的技术架构包含了两大关键部分:辅助潜在模块和文本嵌入模块。辅助潜在模块主要处理输入的文字,包括字形、位置和蒙版图像等,用于生成文本生成或编辑所需的潜在特征。而文本嵌入模块则负责将OCR模型识别的笔划信息与分词器提供的图像标题嵌入相结合,产生能够与背景完美融合的文本效果。这项技术克服了以往在图像文本生成过程中常见的合成文本模糊、无法辨读或错误的问题,极大提升了生成图像文本的准确性。
AnyText工作环境展示

AnyText的主要特点
- 多语言支持:AnyText能够生成包括中文、英文、日文、韩文在内的多种语言文本。
- 多行文本生成:支持用户在图像的不同位置生成多行文段。
- 变形区域书写:能够处理水平、垂直乃至曲线或非规则区域中的文本生成。
- 文本编辑能力:提供对图像中特定位置文本内容的编辑功能,确保文本风格的一致性。
- 易于集成:AnyText的设计便于它与现有的扩散模型无缝对接,增强了模型的文本生成功能。
深入了解AnyText的工作原理
AnyText的工作原理基于精心设计的多个协同工作的模块:
- 文本控制扩散管道:模型首先利用变分自编码器(VAE)对输入图像进行编码,然后通过扩散算法逐渐引入噪声,形成一系列噪声潜在图像。在每一步骤中,TextControlNet网络预测出应该添加到噪声图像上的细节,引导文本的生成。
- 辅助潜在模块:该模块输入字形、位置和掩膜图像,创建出辅助的特征图,它与TextControlNet网络协同工作以生成文本内容。
- 文本嵌入模块:利用OCR模型提取文字笔划信息,再与标题嵌入结合,形成与图像背景融为一体的文本。
- 文本感知损失:用于训练过程中,以提高文本生成的准确性,只针对文本区域而非其他图像特征进行优化。
- 训练和优化:目标是最小化文本控制扩散损失和文本感知损失的加权总和,通过调整权重来取得两种损失的平衡。
如何使用AnyText生成文本
生成文本的过程非常简单快捷:
- 访问AnyText在ModelScope上的空间或者Hugging Face的演示页面。
- 输入您想要转化的Prompt,选择您需要文字出现的图片区域。
- 点击运行,等待系统将根据您的指令生成图片和相应的文本。
获取更多信息
通过上述步骤,用户可以快速地利用AnyText将他们的文本请求转化为准确的图像呈现,无论是用于广告设计、个性化内容创建还是其他需要图像中集成文本的应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号