探索DiffusionGPT:前沿的文本到图像生成技术
简介
在当今的技术前沿领域中,DiffusionGPT是一项突破性的成果。这个由字节跳动的AI团队与中山大学的学者联合开发的系统,是一个依托于大型语言模型(LLM)的开源项目,它专注于解决文本到图像生成过程中的多种挑战。DiffusionGPT不仅能够处理复杂的文本输入,还能够生成高质量、多样化的图像作品。

关于DiffusionGPT
为了更深入地了解DiffusionGPT,以下是一些关于这个系统的重要资源链接:
- 项目主页:DiffusionGPT官网
- 学术研究:Arxiv研究论文
- 代码访问:GitHub代码库
- 在线演示:Hugging Face运行地址
- 高级演示版:DiffusionGPT-XL Demo
DiffusionGPT的核心特性
DiffusionGPT的先进性在于其以下几个主要特点:
- 文本提示解析能力:系统能够精准地理解和解读各种文本类型,无论是基础描述、复杂指令、创意启发还是假设性内容,都能得到适宜的处理。
- 模型选择与集成:运用思维树技术,DiffusionGPT构建了多专家生成模型的层次结构,实现对模型的精细管理和选择。
- 人类反馈优化路径:通过优势数据库,系统利用人类的反馈对模型选择过程进行优化,以提升生成图像的品质。
- 图像生成的精细执行:DiffusionGPT在选定模型后,利用提示扩展技术提升生成图像的细节和艺术性。
- 多领域应用的广泛适用性:DiffusionGPT不仅限于简单描述,还能处理复杂指令和启发性内容,适用于多种使用场景。
- 即插即用的设计:作为一款训练免费、易于集成的解决方案,DiffusionGPT可以便利地融入现有的图像生成流程。
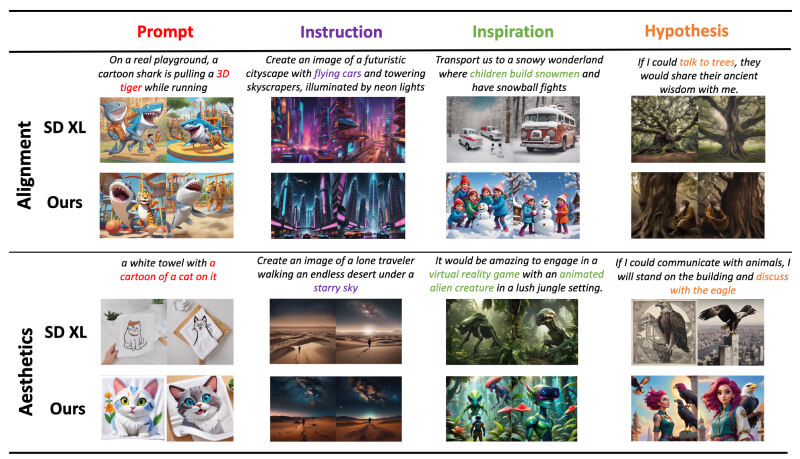
DiffusionGPT的工作原理
DiffusionGPT的图像生成过程遵循以下四个关键步骤:
- 提示解析:利用LLM分析和提取文本提示的核心信息,以确保生成的图像准确反映用户的需求。
- 思维树构建与模型搜索:在提示解析后,通过思维树结构分类和选择最优的生成模型。
- 模型选择:依据优势数据库中的评分和语义相似度,选择最合适的模型以生成图像。
- 生成执行:选定模型与提示扩展代理共同工作,生成细节丰富、艺术性高的图像作品。
通过这些细致的步骤,DiffusionGPT确保了从文本到图像的转化既准确又富有创造性,满足用户对图像质量的高标准要求。
DiffusionGPT不仅仅是一个工具,它代表了当前文本到图像生成技术的一个新高度,为研究人员和开发者打开了探索新领域的大门。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


AI工具箱,全方位AI资源聚合平台,精选全球3000+优质免费AI应用,涵盖ppt生成, AI写作、AI编程、AI绘画、AI设计、AI论文、AI视频、AI配音、AI音乐、AI金融等多个领域领域的AI工具软件。包含扣子、扣子空间、DeepSeek、Gamma等热门AI工具。致力于让AI技术触手可及,助力用户高效工作,加速技术创新与产业应用落地,推动人工智能应用革新。

 鄂公网安备42010402001699号
鄂公网安备42010402001699号